Publications
- Total Number of peer-reviewed publications: 70
- Journals: 46
- Conferences: 23
- Book Chapter: 1
2026
-
-
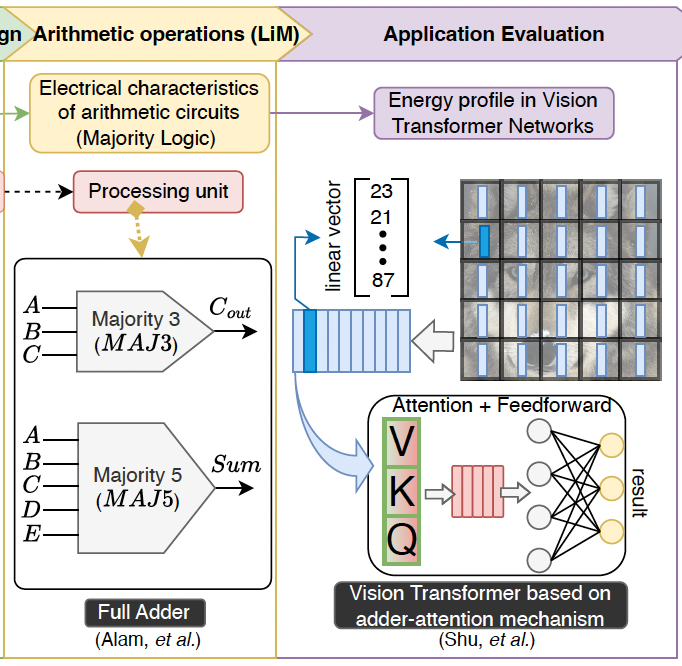
AM5: Bulk Logic-in-Memory Using MRAM NAND Crossbar
C. Mosquera, E. Garzón, M. Lanuzza, A. Teman, L. Yavits
IEEE Journal on Emerging and Selected Topics in Circuits and Systems (JETCAS), 2026
BIB ABSTRACT
Application domains, such as machine learning and big data analytics, impose significant computational challenges to contemporary Von Neumann architectures. To address this issue, logic-in-memory (LiM) has been raised as a promising alternative that targets computing within memory arrays, aimed at alleviating the memory wall, optimizing data transfer, and enabling massive parallelism. Spin-transfer torque magnetic tunnel junction (STT-MTJ) based memory is an emerging memory technology that enables efficient processing using memory. This paper proposes AM5, a novel LiM architecture leveraging MRAM NAND crossbar technology to support in-memory arithmetic operations efficiently. The proposed LiM scheme is designed using a commercial 28nm process node and a Verilog-A-based double-barrier MTJ compact model. Evaluation results show that AM5 consumes about 98 fJ/40.7 fJ/DMTJ per evaluation/write cycle (4.2-4.4 ns/1.9 ns). Additionally, the proposed architecture proposes an in-situ error correction mechanism to mitigate variability, yielding reliable arithmetic operations. These findings show better energy (∼ 6× lower, on average) and competitive latency (∼ 1.3× faster, on average) figures of AM5 compared to other LiM designs based on MTJ-based technology. When used as a LiM unit to perform inference in adder attention Vision Transformer networks, AM5 consumes about one-tenth of the energy required by a processor-centric unit.
-

-
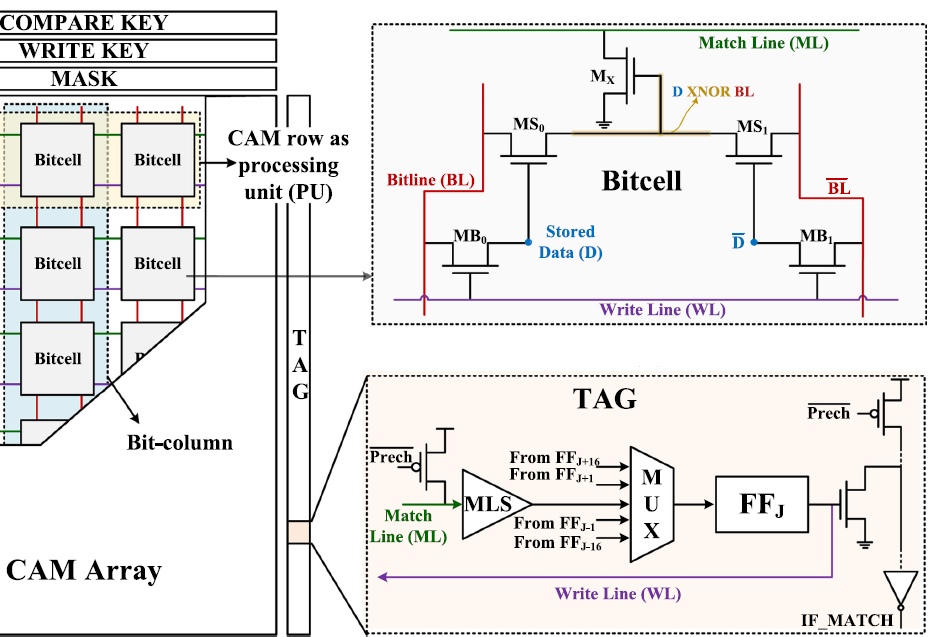
IMAP: In-MRAM Associative Processor with reliable bit-serial massively-parallel arithmetic operations
E. Garzón, C. Mosquera, M. Lanuzza
Spintronics and Nanomagnetism Conference - SPIE Photonics Europe (INVITED), 2026
BIB ABSTRACT
The ever-growing demand for data-intensive applications has driven the adoption of in-memory computing (IMC) as a promising paradigm to overcome the von Neumann bottleneck of conventional computing architectures. Among the emerging memory technologies explored for IMC-based architectures, magnetic random-access memory (MRAM) stands out due to its non-volatility, high endurance, and compatibility with standard CMOS fabrication process. This work presents IMAP, an in-MRAM associative processor based on perpendicular anisotropy double-barrier magnetic tunnel junctions (DMTJs) with two reference layers. IMAP presents processing units built with NAND-type content-addressable memory (CAM) architecture, allowing bit-serial massivelyparallel arithmetic operations. Reliable and energy-efficient in-memory computing operations are achieved by properly carrying out a data allocation technique to mitigate variability-induced errors arising from the limited ratio between high-resistance and low-resistance states. IMAP is designed using a commercial 28 nm process and a Verilog-A-based compact DMTJ model calibrated with experimental physical parameters. Circuit-level Monte Carlo simulations demonstrate correct operation under worst-case conditions and show that the proposed data allocation increases the probability of correct 8-bit full-adder operations for the most significant bits from about 63% to approximately 95%. At the application level, IMAP is evaluated as an accumulator in a fixed-point twodimensional convolution workload, where the proposed approach improves the output peak signal-to-noise ratio from 6.21 dB to 24.26 dB. The obtained results indicate that IMAP can efficiently accelerate arithmetic kernels associated with contemporary data-centric applications, thereby suggesting MRAM-based associative processing as a potential IMC architecture for future memory-centric computing systems.
-
-
SPARCAM: Sparse Matrix Multiplication Accelerator Using Multi-Port Dynamic CAM
E. Garzón, B. Zambrano, D. Sheinenzon, M. Lanuzza, A. Teman, L. Yavits
Journal of Systems Architecture (JSA), 2026
BIB ABSTRACT
Sparse General matrix multiplication (SpGEMM) is a fundamental kernel in many scientific and engineering fields, including Generative AI. However, its intrinsic computation complexity presents substantial challenges, making efficient hardware implementation particularly difficult. This paper proposes SPARCAM, a novel SpGEMM accelerator, developed and optimized for very energy-efficient Generative AI edge applications. SPARCAM is designed using low-power dense Gain Cell embedded DRAM (GC-eDRAM) technology, a processing near memory paradigm, and a modified outer product matrix multiplication algorithm. Despite its quite limited peak theoretical performance, SPARCAM achieves very high energy efficiency due to its low-power architecture and almost 100% utilization of its computing resources. Designed in a commercial 28nm FDSOI technology, SPARCAM achieves 13.9× speedup over a high-performance embedded CPU when processing large-scale sparse matrices. When multiplying limited-size sparse matrices, SPARCAM obtains 193× speedup over high-performance GPU. SPARCAM reaches about 4.3 orders-of-magnitude, on average, higher energy benefits, and 1892×, 181×, 2×, and 3471×, higher energy efficiency (over CPU) compared with state-of-the-art SpGEMM accelerators SpArch, OuterSPACE, MatRaptor, and high-performance GPU, respectively.
-
-
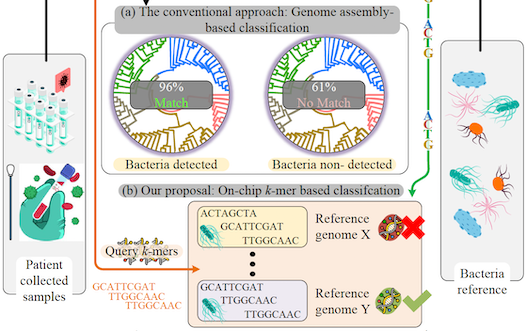
CADM: Content Addressable Commodity Off-the-Shelf DRAM-Based Genome Classifier
E. Garzón, A. Fish, L. Yavits
Journal of Systems Architecture (JSA), 2026
BIB ABSTRACT
Processing using memory (PuM) leverages analog properties of memory infrastructure to implement logic and arithmetic operations. Commodity Off-The-Shelf (COTS) DRAM is particularly attractive for PuM because it requires no device modification, thereby preserving the ubiquity, availability, and cost advantages of modern DRAM while enabling massive column-level parallelism. We propose CADM (Content-Addressable DRAM), that enables exact and approximate (similarity) search in- and usingunmodified COTS DRAM. CADM targets genome classification, which is one of the most important applications in bioinformatics. Specifically, rapid and accurate detection of bacterial pathogens is critical for effective clinical decision-making, particularly in life-threatening conditions such as sepsis, where early identification of the causative agent significantly improves patient outcomes. We implement CADM in commercial DDR4 and show that it can achieve up to 185× higher throughput and 73× energy savings compared to CPU-run state-of-the-art classifier Kraken2. Using approximate search, CADM can achieve 9× higher F1 score when matching relatively short (<32 DNA bases) ambiguous and erroneous k-mers.
-
-
Integrated BSI Bacteria Identifier-On-Chip Using Approximate k-mer Matching
E. Garzón, V. Galindo, Y. Harary, A. Teman, L. Yavits
Scientific Reports, 2026
BIB ABSTRACT
Acute graft-versus-host (GVHD) is a deadly disease that can be treated through fecal microbiota transplantation. However, such treatment is often followed by life-threatening bloodstream infections (BSI). Rapid detection of BSI-causing bacteria is critical in preventing BSI-related deaths. PC-CAM is a pathogen identification system-on-chip designed to assist in avoiding BSI by real-time detection of pathogen bacterial genomes using k-mer matching. The core of PC-CAM is an Approximate search-capable (Hamming distance tolerant) Content Addressable Memory (ACAM). PC-CAM was designed and manufactured in a commercial 65nm process. We use PC-CAM for real-time detection of bacteria in blood and stool samples of GVHD patients and evaluate PC-CAM bacteria identification efficiency, performance, silicon area, and power consumption based on silicon measurements. PC-CAM is capable of classifying 960K short DNA reads/sec within a silicon area of 2.38mm2 consuming about 1.27mW. We envision PCCAM as a platform deployed at points of care to provide real-time, accurate, privacy-preserving, easy-to-operate, and energy-efficient pathogen classification.
-
-
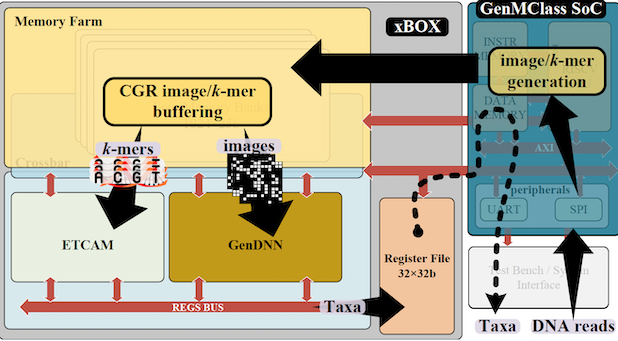
GenMClass: Design and comparative analysis of genome classifier-on-chip platform
D. Bromot, Y. Kra, Z. Jahshan, E. Garzón, A. Teman, L. Yavits
Journal of Systems Architecture (JSA), 2026
BIB ABSTRACT
We propose GenMClass, a genome classification system-on-chip (SoC) implementing two different classification approaches and comprising two separate classification engines: a DNN accelerator GenDNN, that classifies DNA reads converted to images using a classification neural network, and a similarity search-capable Error Tolerant Content Addressable Memory ETCAM, that classifies genomes by k-mer matching. Classification operations are controlled by an embedded RISCV processor. GenMClass classification platform was designed and manufactured in a commercial 65nm process. We conduct a comparative analysis of ETCAM and GenDNN classification efficiency as well as their performance, silicon area and power consumption using silicon measurements. The size of GenMClass SoC is 3.4mm2 and its total power consumption (assuming both GenDNN and ETCAM perform classification at the same time) is 144mW. This allows using GenMClass as a portable classifier for pathogen surveillance during pandemics, food safety and environmental monitoring, agriculture pathogen and antimicrobial resistance control, in the field or at points of care.
-
-
PatBiNN: A 65nm Processing-in-CAM Based BNN Implementation for Pathogen Genome Classification
Y. Harary, A. Sharoni, E. Garzón, L. Yavits
2026 Design, Automation & Test in Europe Conference (DATE), 2026
BIB ABSTRACT
Binary Neural Networks (BNNs) are a cost-effective and highly efficient alternative to traditional neural networks. Genome classification is a frequent component of genome analysis pipelines, with a variety of applications spanning pandemic preparedness, AMR resistance control, drinking water and food safety. PatBiNN is a BNN based pathogen genome classifier optimized for edge and field use. It employs a binary multilayer perceptron (MLP) implemented using in-Hamming distance tol- erant (similarity search) content addressable memory processing. PatBiNN was designed and manufactured in a commercial 65nm process. It achieves F1 score of 88%, ROC AUC of 0.986, throughput of 0.8M inferences/s, power consumption of 4.8 mW and energy efficiency of 237TOPs/s/W with silicon area of 0.87mm2.
2025
-
-
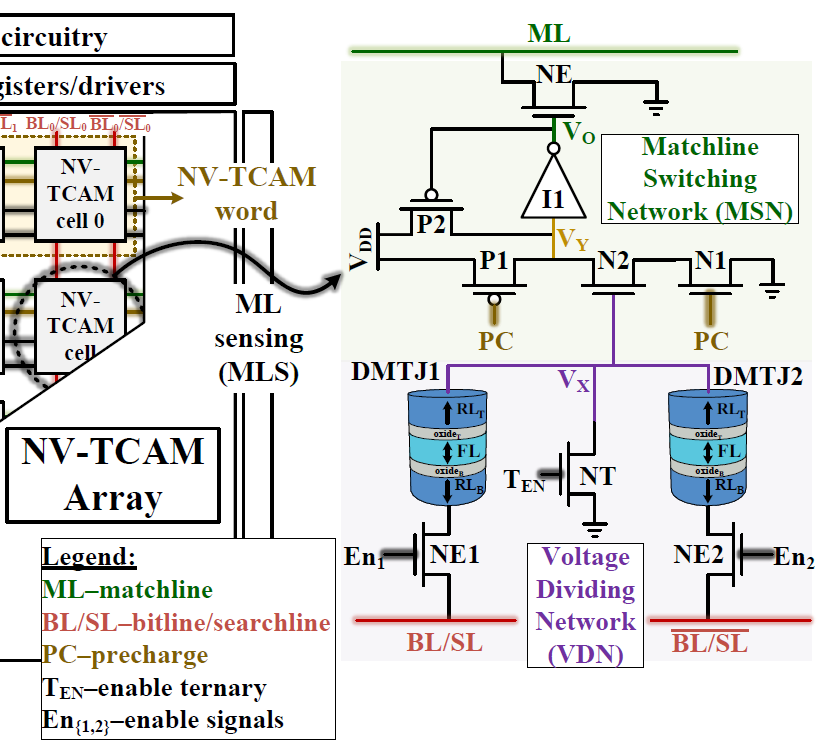
NV-PCAM: Non-Volatile Precharge-Free Content-Addressable Memory
O. Caisaluisa, E. Garzón, E. Holguín, M. Lanuzza, L.M. Prócel
IEEE Transactions on Circuits and Systems I: Regular Papers (TCAS-I), 2025
BIB ABSTRACT
Content-addressable memories (CAMs) are a class of associative memories known for their capability to perform massively parallel comparisons between an input query pattern and the entire memory content. In the past decade, the increasing demand for high-performance and energy-efficient computing systems has generated significant interest in non-volatile CAMs (NV-CAMs) based on emerging non-volatile memory devices. In this work, we propose a novel non-volatile, precharge-free CAM (NV-PCAM) scheme based on double-barrier magnetic tunnel junctions (DMTJs). When compared to its counterparts, NV-PCAM presents competitive figures of merit in terms of area, speed, and energy efficiency, while also ensuring low search error rates. We also provide a complete class of voltage-divider-based NV-CAM cells for benchmark comparison. All schemes are designed and laid out using a 65 nm process and evaluated under Monte Carlo and process-voltage-temperature (PVT) simulations. Through Monte Carlo simulations, the proposed NV-PCAM demonstrates up to 81% and 85% lower search energy than NV-NOR and NV-NAND, respectively, as well as a 61% and 16% improvement in terms of search delay with a compact cell area footprint.
-
-
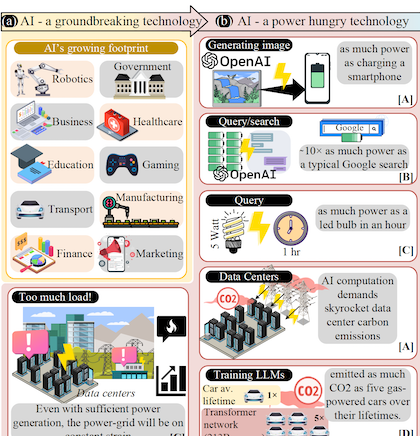
Hardware Accelerators For A Sustainable AI Future
E. Garzón
IEEE International Conference on Application of Information Technologies in Engineering, Management and Science (ICAI-TEMS), 2025
BIB ABSTRACT
The exponential growth of the use of artificial intelligence (AI) in all sectors of our society is driving unprecedented energy consumption and carbon dioxide emissions, threatening both the environment and the scalability of future AI technologies. This growing concern is especially pronounced in the context of transformer-based generative AI models, whose computational and energy demands continue to escalate rapidly. Addressing this challenge necessitates a shift from contemporary computing through the integration of novel computing paradigms and specialized hardware accelerators that significantly improve performance-per-watt efficiency. This work discusses the power-intensive nature of generative AI technologies, reviews current trends in AI hardware, and provides a forward-looking perspective on hardware accelerators, with a particular emphasis on memory-centric computing, specifically optimized for AI applications. By reviewing algorithmic and architectural advances, this work shows the central role of hardware innovation in enabling energy-efficient and scalable generative AI systems.
-
-
A Physical Unclonable Function based on Differential Subthreshold PMOS Array with 9.73x10-4 Stabilized BER and 1.3pJ/bit in 65nm
B. Zambrano, S. Strangio, E. Garzón, A. Catania, G. Iannaccone, M. Lanuzza
Journal of Low Power Electronics and Applications (JLPEA), 2025
BIB ABSTRACT
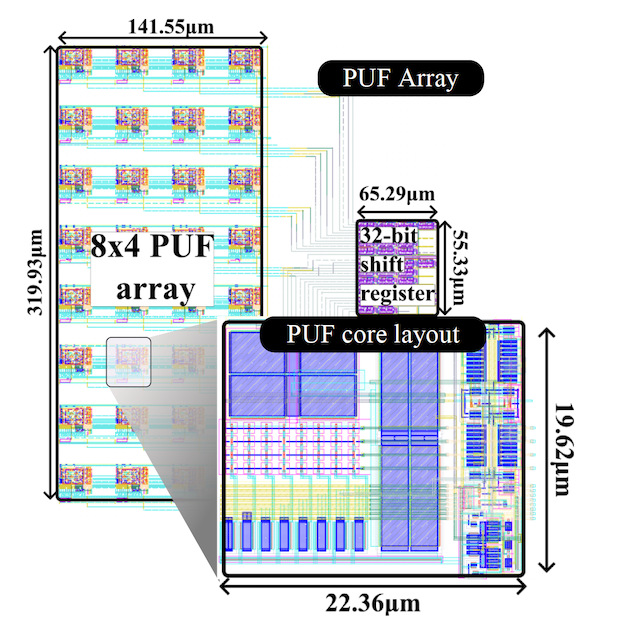
This paper introduces a physical unclonable function (PUF) based on a differential array of minimum-sized PMOS devices. Each response bit is obtained by comparing the two analog outputs of the differential array through a dynamic comparator with a trimmable offset. This latter is effectively used to mask potentially unstable response bits. To further improve PUF reliability, spatial majority voting is also implemented, resulting in near zero (< 3.12x10-9) bit error rate (BER) at 1.2V and 25°C. Under variations of supply voltage (0.8V-1.3V) and temperature (0°C-75°C), the native bit error rate of 3.5% is reduced to 9.73x10-4 after stabilization, consuming only 1.37 pJ per output bit
-
-
High-performance and reliable probabilistic Ising machine based on simulated quantum annealing
E. Raimondo, E. Garzón, Y. Shao, A. Grimaldi, S. Chiappini, R. Tomasello, N. Davila-Melendez, J.A. Katine, M. Carpentieri, M. Chiappini, M. Lanuzza, P. Khalili Amiri, G. Finocchio
Physical Review X (PRX), 2025
BIB ABSTRACT
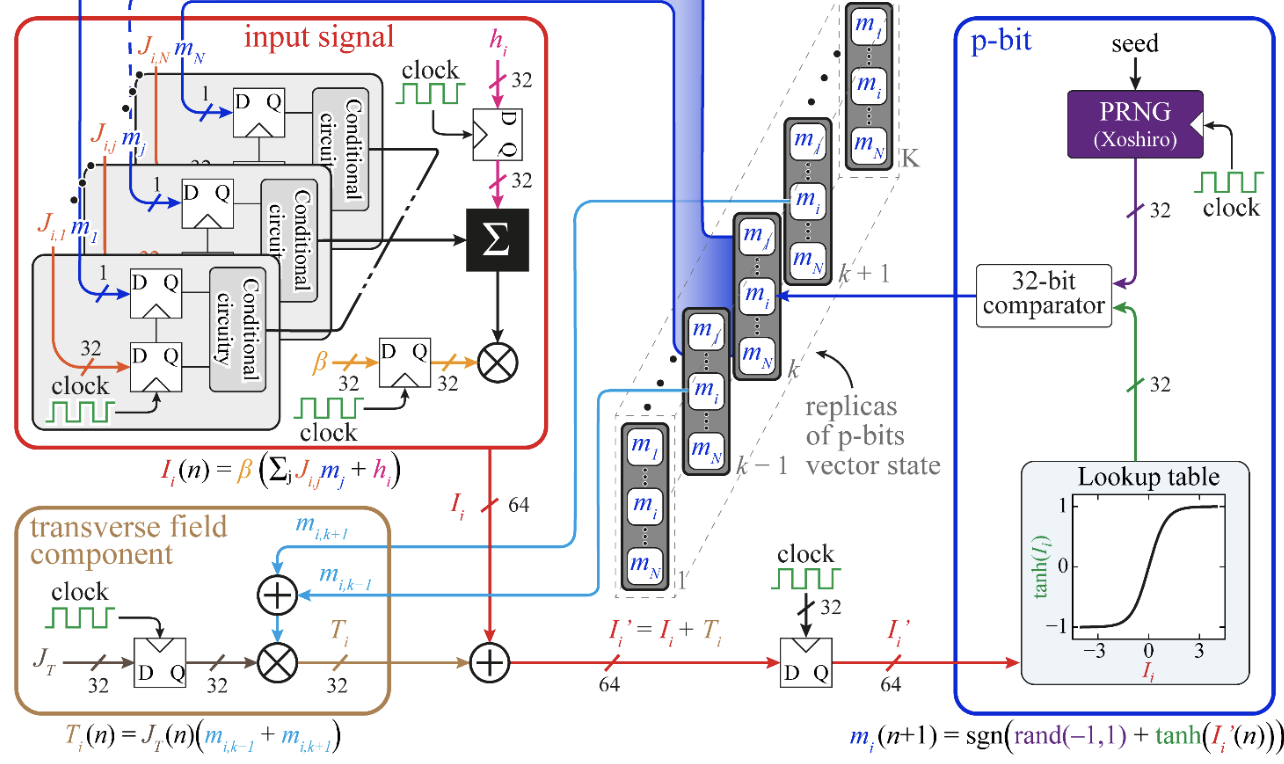
Probabilistic computing with p-bits is emerging as a computational paradigm for machine learning and for facing combinatorial optimization problems (COPs) with the so-called probabilistic Ising machines (PIMs). From a hardware point of view, the key elements that characterize a PIM are the random number generation, the nonlinearity, the network of coupled p-bits, and the energy minimization algorithm. Regarding the latter, in this work we show that PIMs using the simulated quantum annealing (SQA) schedule exhibit better performance as compared to simulated annealing and parallel tempering in solving a number of COPs, such as maximum satisfiability problems, planted Ising problem, and travelling salesman problem. Additionally, we design and simulate the architecture of a fully connected CMOS-based PIM able to run the SQA algorithm having a spin- update time of 8 ns with a power consumption of 0.22 mW. Our results also show that SQA increases the reliability and the scalability of PIMs by compensating for device variability at an algorithmic level enabling the development of their implementation combining CMOS with different technologies such as spintronics. This work shows that the characteristics of the SQA are hardware-agnostic and can be applied in the co-design of any hybrid analog-digital Ising machine implementation. Our results open a promising direction for the implementation of a new generation of reliable and scalable PIMs.
-
-
A Low-Power 4-bit Tracking-Type Analog-to-Digital Converter in SKY130 Process
E. Astudillo, E. Holguín, E. Garzón, L.M. Prócel
IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), 2025
BIB ABSTRACT
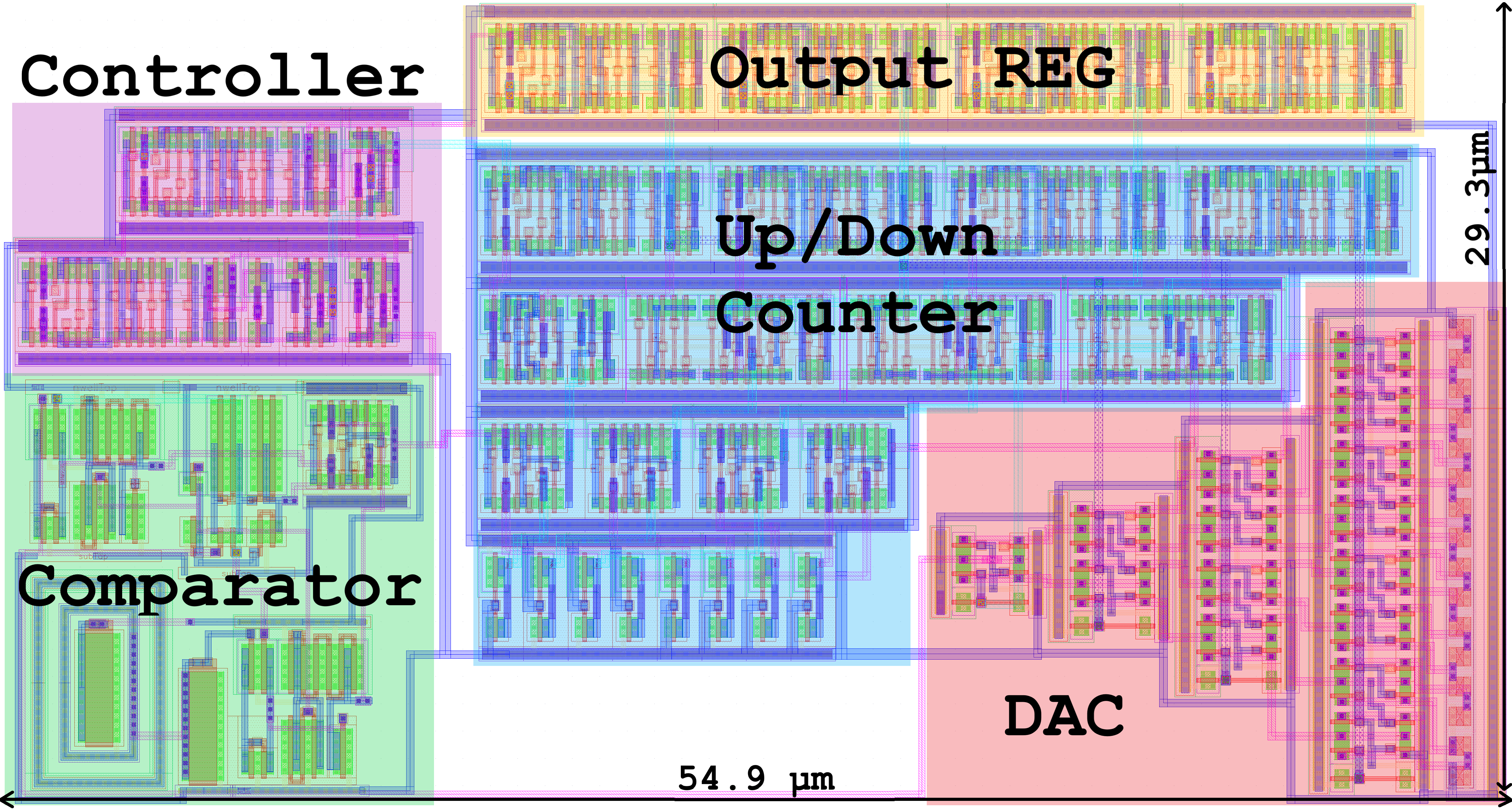
This paper presents the design and full-custom layout implementation of a 4-bit Tracking-Type Analog-to-Digital Converter (TT-ADC) using the SKY130 130 nm CMOS process. The proposed architecture mainly integrates a rail-to-rail analog comparator and a multiplexed resistor-string Digital-to-Analog Converter (DAC), combined with a synchronous controller and an output register. Unlike traditional tracking ADCs, this work introduces a fully integrated mixed-signal design optimized for both bandwidth and power efficiency, and evaluated under process-temperature-voltage variations accounting for layout parasitics. Simulations show that the proposed TT-ADC presents a bandwidth of 150 MHz while consuming only 505μ W of power. Compared to prior 4-bit implementations, the proposed design achieves over 2× improvement in bandwidth and an 87% reduction in power consumption. The area footprint is about 54.9μm×29.3μm, making it highly suitable for energyconstrained, high-speed embedded applications.
-
-
PiC-BNN: A 128-kbit 65nm Processing-in-CAM-Based End-to-End Binary Neural Network Accelerator
Y. Harary, A. Sharoni, E. Garzón, M. Lanuzza, A. Teman, L. Yavits
IEEE Cross-Disciplinary Conference on Memory-Centric Computing (CCMCC), 2025
BIB ABSTRACT
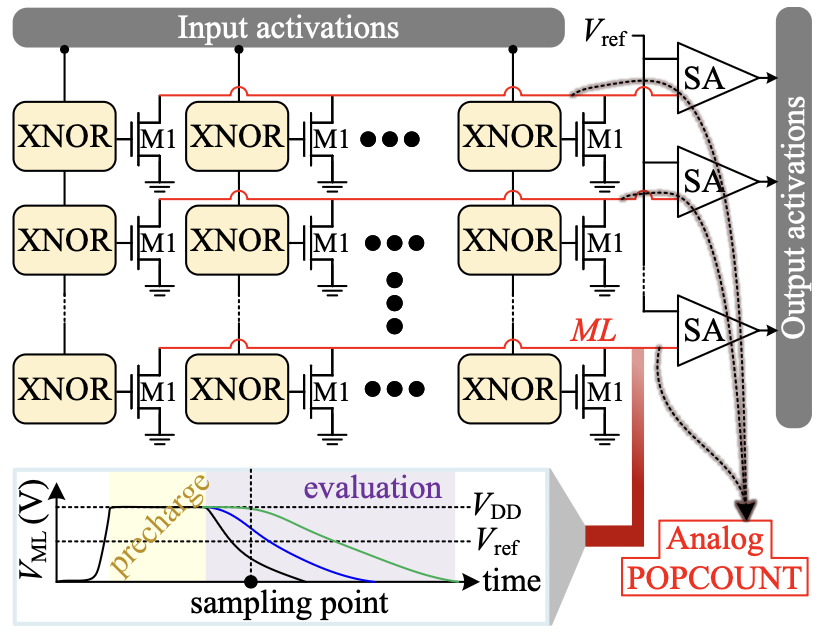
Binary Neural Networks (BNNs), where weights and activations are constrained to binary values (+1, -1), are a highly efficient alternative to traditional neural networks. Unfortunately, typical BNNs, while binarizing linear layers (matrix-vector multiplication), still implement other network layers (batch normalization, softmax, output layer, and sometimes the input layer of a convolutional neural network) in full precision. This limits the area and energy benefits and requires architectural support for full precision operations. We propose PiC-BNN, a true end-to-end binary in-approximate search (Hamming distance tolerant) Content Addressable Memory based BNN accelerator. PiC-BNN is designed and manufactured in a commercial 65nm process. PiC-BNN uses Hamming distance tolerance to apply the law of large numbers to enable accurate classification without implementing full precision operations. PiC-BNN achieves baseline software accuracy (95.2%) on the MNIST dataset and 93.5% on the Hand Gesture (HG) dataset, a throughput of 560K inferences/s, and presents a power efficiency of 703M inferences/s/W when implementing a binary MLP model for MNIST/HG dataset classification.
-
-
An Accurate And Low Complexity Offset Calibration Methodology for Dynamic Comparators
J. Cuenca, B. Zambrano, E. Garzón, L.M. Prócel, M. Lanuzza
Journal of Low Power Electronics and Applications (JLPEA), 2025
BIB ABSTRACT
Dynamic comparators play an important role in electronic systems, requiring high accuracy, low power consumption, and minimal offset voltage. This work proposes an accurate and low-complexity offset calibration design based on a capacitive load approach. It was designed using a 65nm CMOS technology and comprehensively evaluated under Monte Carlo simulations and PVT variations. The proposed scheme was built using MIM capacitors and transistor-based capacitors, and includes Verilog-based calibration algorithms. The proposed offset calibration is benchmarked, in terms of precision, calibration time, energy consumption, delay, and area, against prior calibration techniques: current injection via gate biasing by a charge pump circuit, and current injection via parallel transistors. The evaluation of the offset calibration schemes relies on Analog/Mixed-Signal (AMS) simulations, ensuring accurate evaluation of digital and analog domains. The charge pump method achieved the best Energy-Delay Product (EDP) at the cost of lower long-term accuracy, mainly because of its capacitor leakage. The proposed scheme demonstrated superior performance in offset reduction, achieving a 1-sigma offset of 0.223mV, while maintaining precise calibration. Among the calibration algorithms, the window algorithm performs better than the accelerated calibration. This is mainly because the window algorithm considers noise-induced output oscillations, ensuring consistent calibration across all designs. This work provides insights into the trade-offs between energy, precision, and area in dynamic comparator designs, offering strategies to enhance offset calibration.
-
-
CAM4: In-Memory Viral Pathogen Genome Classification using Similarity Search Dynamic Content-Addressable Memory
Z. Jahshan, I. Merlin, E. Garzón, L. Yavits
IEEE Transactions on Emerging Topics in Computing (TETC), 2025
BIB ABSTRACT
We present CAM4, a novel embedded dynamic storage-based similarity search content addressable memory. CAM4 is designated for in-memory computational genomics applications, particularly the identification and classification of pathogen DNA. CAM4 employs a novel gain cell design and onehot encoding of DNA bases to address retention time variations, and mitigate potential data loss from pulldown leakage and soft errors in embedded DRAM. CAM4 features performance overhead-free refresh and data upload, allowing simultaneous search and refresh without performance degradation. CAM4 offers approximate search versatility in scenarios with a variety of industrial sequencers with different error profiles. When classifying DNA reads with a 10% error rate, it achieves, on average, a 25% higher F1 score compared to MetaCache-GPU and Kraken2 DNA classification tools. Simulated at 1GHz, CAM4 provides 1, 412× and 1, 040× average speedup over MetaCacheGPU and Kraken2 respectively.
-
-
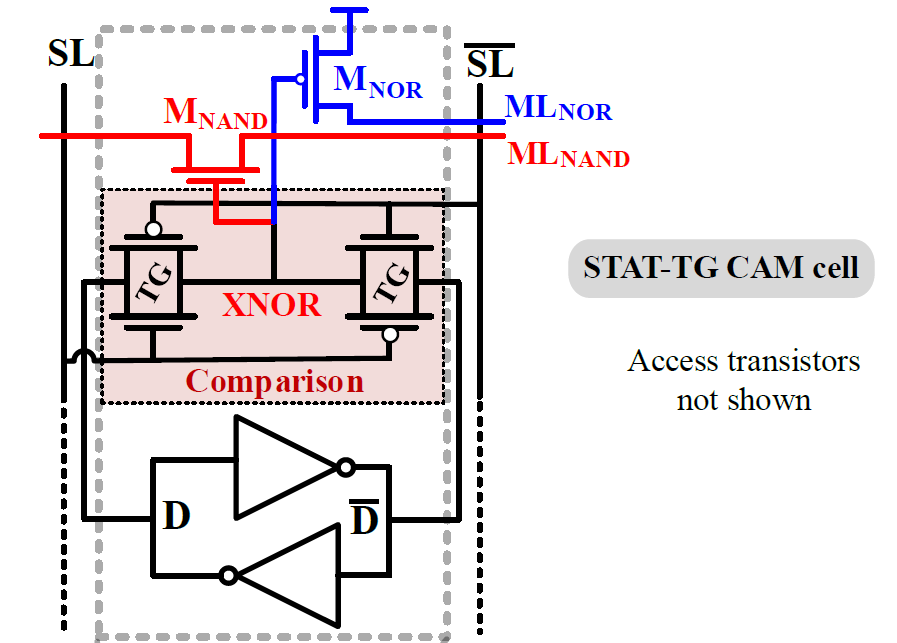
Towards Low-Power High-Performance Content-Addressable Memory: a Robust Precharge-Free Approach
R. Taco, E. Garzón, A. Teman, L. Yavits, M. Lanuzza
IEEE International Symposium on Circuits and Systems (ISCAS), 2025
BIB ABSTRACT
Low-power high-performance content-addressable memories (CAMs) are important components in modern computing systems. In this work, we present a robust CAM that overcomes the power and performance limitations of conventional precharge-based CAMs. The proposed static transmission gatebased (STAT-TG) CAM design achieves low-power operation comparable to NAND CAMs while maintaining search speeds rivaling those of NOR CAMs. The STAT-TG CAM was designed using a 65nm CMOS technology and comprehensively evaluated under extensive Monte Carlo simulations. Compared to conventional CAMs, the STAT-TG CAM is 14% faster than NAND CAM, while consuming only 25% of the energy per operation relative to NOR CAM. This makes STAT-TG CAM a promising solution for high-performance yet energy-efficient applications.
-
-
Low Matchline Voltage Swing Content-Addressable Memory Cell
C. Mosquera, R. Taco, B. Zambrano, LM. Prócel, E. Garzón, M. Lanuzza
IEEE International Symposium on Circuits and Systems (ISCAS), 2025
BIB ABSTRACT
Content-addressable memory (CAM) is a specialized memory architecture designed for fast data searches, allowing a one-clock-cycle comparison between the search input and the entire memory content. In this work, a low matchline voltage swing CAM is proposed to reduce the search power consumption while maintaining high-speed search operations. Low voltage swing in the matchline is enabled by introducing extra circuitry in the conventional CAM cell. By means of comprehensive Monte Carlo and post-layout simulations using a commercial 65 nm node, we show that the proposed CAM cell design allows for robustness against process, voltage, and temperature variations without the need for dedicated matchline sense schemes. Compared to conventional precharge high NOR-type CAM, the proposed design achieves 42% higher speed and 29.1% less energy consumption. Post-layout results demonstrate that the proposed CAM operates reliably at 0.6V, maintaining performant and reliable search operations across a wide temperature range.
-
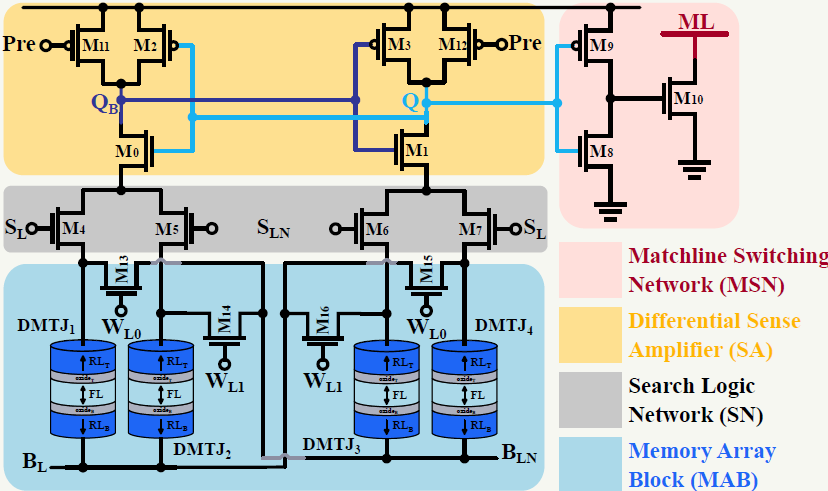
-
Non-Volatile Content-Addressable Memory for Energy-Efficient & High-Performance Search and Update Operations
A. Bedoya, B. Zambrano, R. Taco, LM. Prócel, M. Lanuzza, E. Garzón
IEEE International Symposium on Circuits and Systems (ISCAS), 2025
BIB ABSTRACT
This work presents a non-volatile contentaddressable memory (NV-CAM) based on double-barrier magnetic tunnel junction technology (DMTJ). Unlike state-ofthe- art NV-CAM designs that present low-performance updates, our NV-CAM allows energy-efficient, high-performance search and update operations. This makes it well-suited for applications requiring a high frequency of searches/updates, such as associative processors. The NV-CAM hybrid CMOS/DMTJ was designed using a commercial 65nm CMOS technology and a Verilog-A-based DMTJ compact model. The NV-CAM evaluation was carried out by employing Monte Carlo simulations while accounting for process variations. Simulation results show that our NV-CAM presents competitive figures of merit compared to state-of-the-art design. Our NV-CAM presents energy-efficient operations and reduces the update and search delay by about 71% and 75%, respectively, compared to other NV-CAMs.
-
-
A 128-kbit Approximate Search-Capable Content-Addressable Memory (CAM) With Tunable Hamming Distance
E. Garzón, E. Rechef, R. Golman, O. Harel, Y. Harary, P. Snapir, M. Lanuzza, A. Teman, L. Yavits
IEEE Journal of Solid-State Circuits (JSSC), 2025
BIB ABSTRACT
The growing need for approximate matching in data-intensive applications, such as data analytics, machine learning, deep learning, and computational genomics has driven the proposal of our Hamming distance (HD) tolerant Content- Addressable Memory (HD-CAM). HD-CAM features a modified NOR-type associative memory cell that leverages the discharge speed of the matchline to directly measure the HD between the stored and the query patterns. This novel approach enables efficient in-memory approximate matching. The proposed design was fabricated in a 65nm technology, running at 125MHz with an operating voltage of 1.2V and consuming approximately 0.2 fJ/bit/search at room temperature. HD-CAM features a userprogrammable HD tolerance threshold, making it particularly efficient for compare-intensive applications, such as genome analysis, text processing, and database processing. Silicon measurements demonstrate that HD-CAM maintains F1 score above 90% under process, voltage, and temperature (PVT) variations across a range of HDs.
-
-
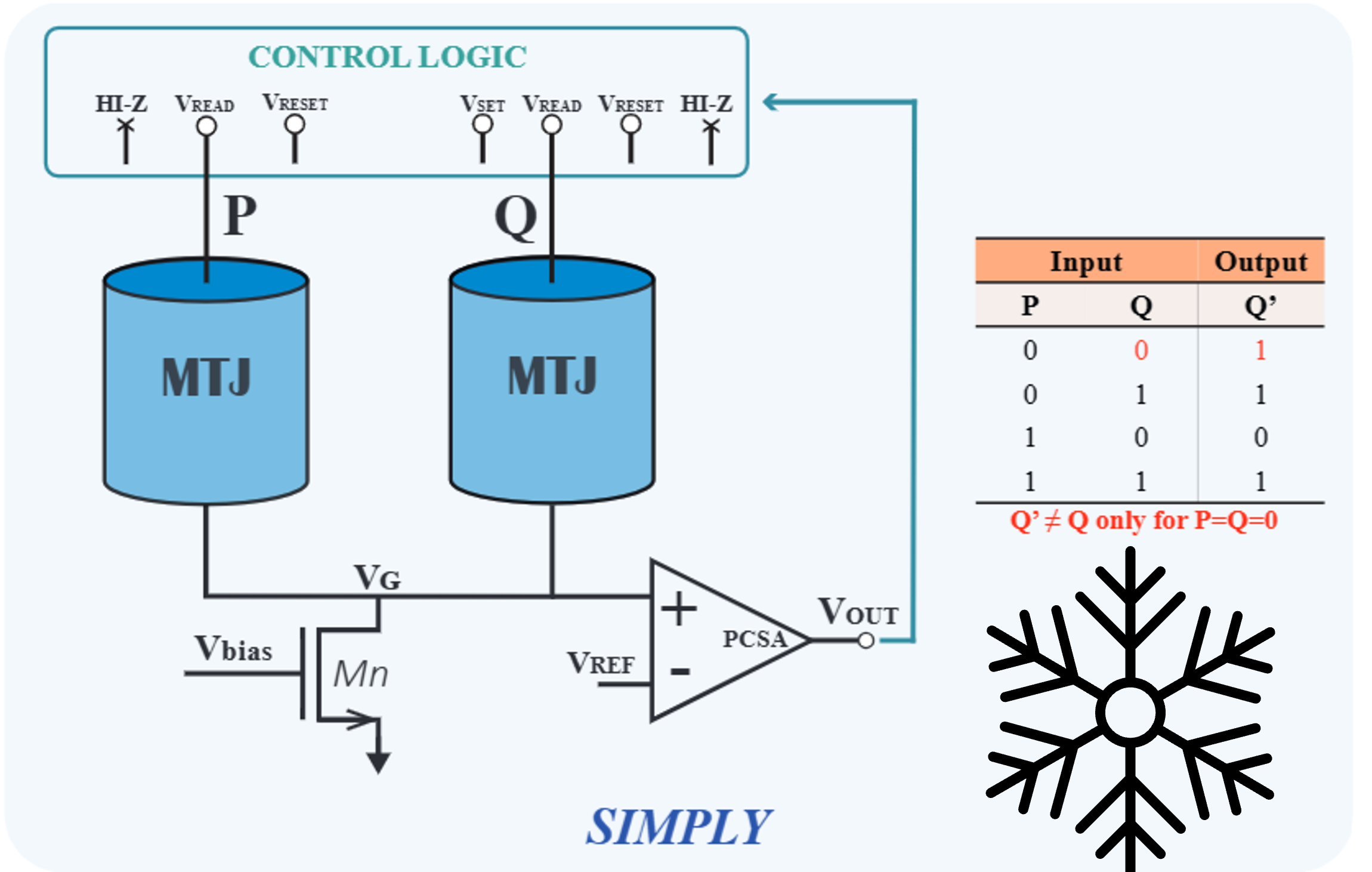
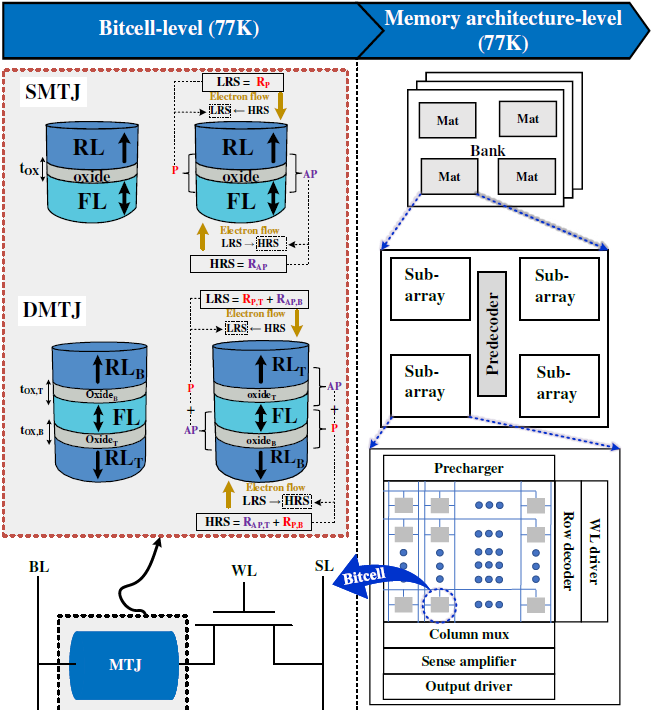
Cryo-SIMPLY: A Reliable STT-MRAM Based Smart Material Implication Architecture For In-Memory Computing
T. Moposita, E. Garzón, A. Teman, M. Lanuzza
Nanomaterials, 2025
BIB ABSTRACT
This paper presents Cryo-SIMPLY, a reliable smart material implication (SIMPLY) operating at cryogenic conditions (77K). The assessment considers SIMPLY schemes based on spin-transfer torque magnetic random access memory (STT-MRAM) technology with single-barrier magnetic tunnel junction (SMTJ) and double-barrier (DMTJ). Our study relies on a temperature-aware macrospin-based Verilog-A compact model for MTJ devices and a 65nm commercial process design kit (PDK) calibrated down to 77K under silicon measurements. The DMTJ-based SIMPLY demonstrates a significant improvement in read margin at 77K, overcoming the conventional SIMPLY scheme at room temperature (300K) by approximately 2.3X. When implementing logic operations with the SIMPLY scheme operating at 77K, the DMTJ-based scheme assures energy savings of about 69%, as compared to its SMTJ-based counterpart operating at 77K. Overall, our results prove that the SIMPLY scheme at cryogenic conditions is a promising solution for reliable and energy-efficient Logic-in-Memory (LIM) architectures.
2024
-
-
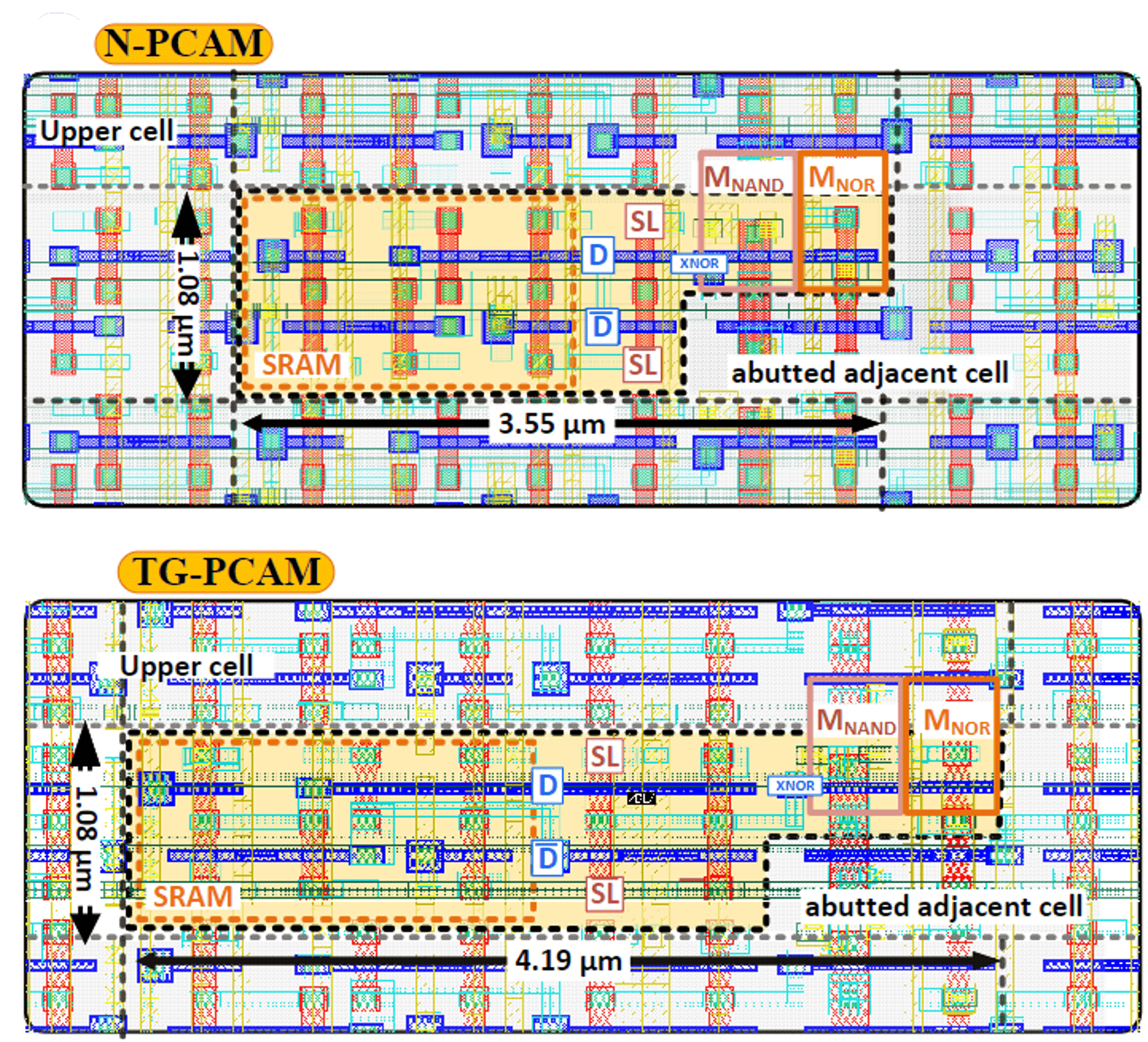
Designing Precharge-Free Energy-Efficient Content-Addressable Memories
R. Taco, E. Garzón, R. Hanhan, A. Teman, L. Yavits, M. Lanuzza
IEEE Transactions on Very Large Scale Integration (VLSI) Systems (TVLSI), 2024
BIB ABSTRACT
Content-addressable memory (CAM) is a specialized type of memory that facilitates massively parallel comparison of a search pattern against its entire content. State-of-the-art CAM solutions are either fast but power-hungry (NOR CAM) or slow while consuming less power (NAND CAM). These limitations stem from the dynamic precharge operation, leading to excessive power consumption in NOR CAMs and charge-sharing issues in NAND CAMs. In this work, we propose a precharge-free CAM (PCAM) class for energy-efficient applications. By avoiding precharge operation, PCAM consumes less energy than a NAND CAM, while achieving search speed comparable to a NOR CAM. PCAM was designed using a 65nm CMOS technology and comprehensively evaluated under extensive Monte Carlo simulations, while taking into account layout parasitics. When benchmarked against conventional NAND CAM, PCAM demonstrates improved search run time (reduced by more than 30%) and 15% less search energy. Moreover, PCAM can cut energy consumption by more than 75% as compared to conventional NOR CAM. We further extend our analysis to the application level, functionally evaluating the CAM designs as a fully-associative cache using a CPU simulator running various benchmark workloads. This analysis confirms that PCAMs represent an optimal energy-performance design choice for associative memories and their broad spectrum of applications.
-
-
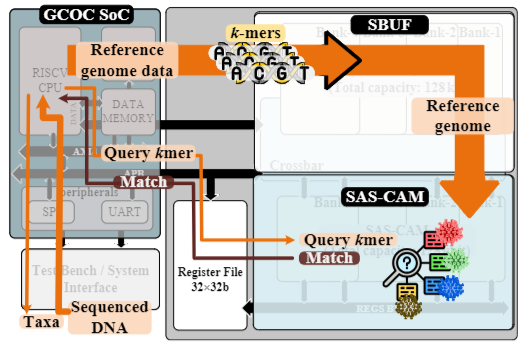
GCOC: A Genome Classifier-On-Chip based on Similarity Search Content Addressable Memory
Y. Harary, P. Snapir, S. Siman Tov, C. Kruphman, E. Rechef, Z. Jahshan, E. Garzón, L. Yavits
IEEE Transactions on Biomedical Circuits and Systems (TBioCAS), 2024
BIB ABSTRACT
GCOC is a genome classification system-on-chip (SoC) that classifies genomes by k-mer matching, an approach that divides a DNA query sequence into a set of short DNA fragments of size k, which are searched in a reference genome database, with the underlying assumption that sequenced DNA reads of the same organism (or its close variants) share most of such k-mers. At the core of GCOC is a similarity, or approximate search-capable Content Addressable Memory (SAS-CAM), which in addition to exact match, also supports approximate, or Hamming distance tolerant search. Classification operation is controlled by an embedded RISC-V processor. GCOC classification platform was designed and manufactured in a commercial 65nm process. We conduct a thorough analysis of GCOC classification efficiency as well as its performance, silicon area, and power consumption using silicon measurements. GCOC classifies 769.2K short DNA reads/sec. The silicon area of GCOC SoC is 3.12mm2 and its power consumption is 1.27mW. We envision GCOC deployed as a field (for example at points of care) portable classifier where the classification is required to be real-time, easy to operate and energy efficient.
-
-
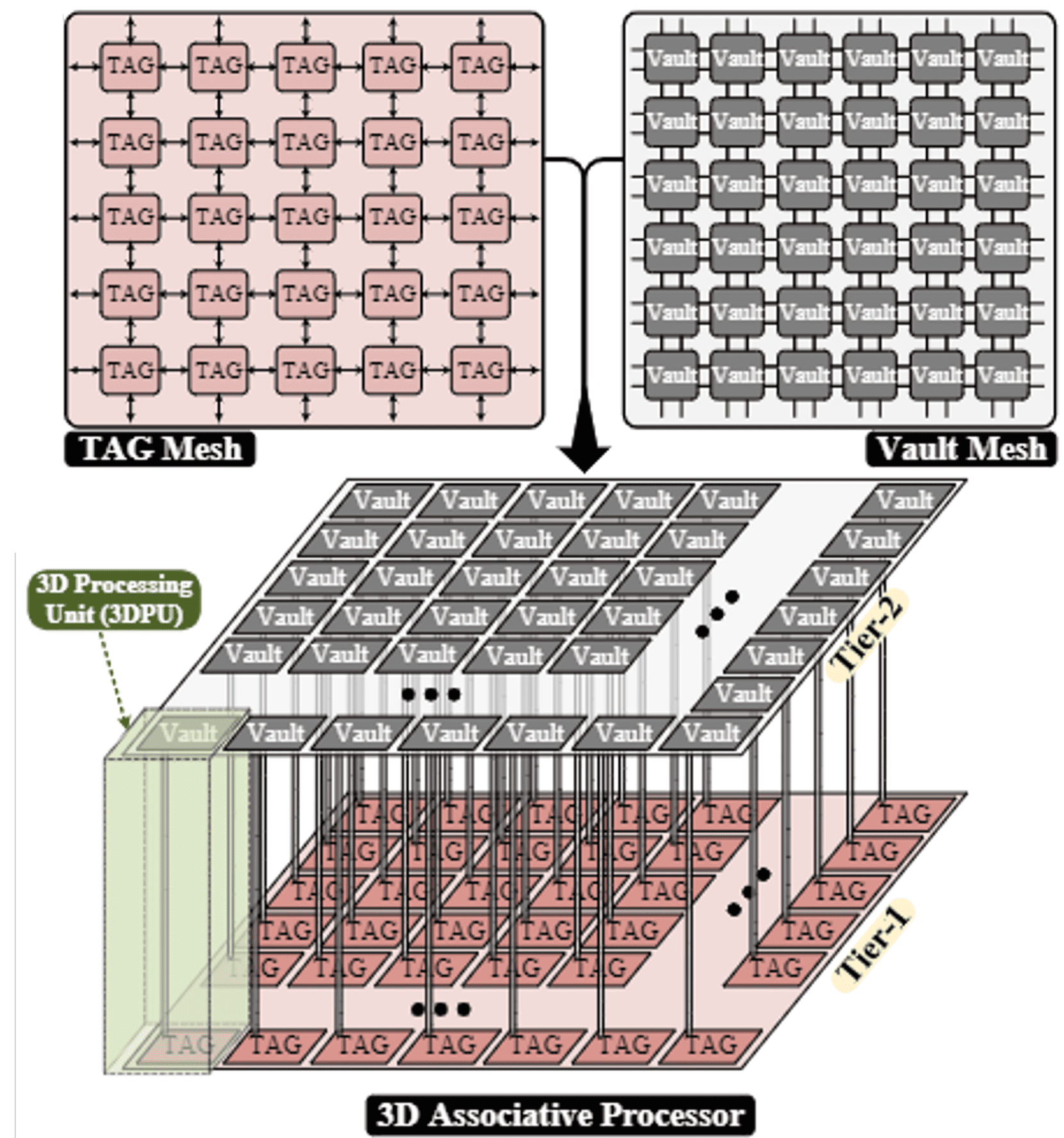
Monolithic 3D-Based Non-Volatile Associative Processor For High-Performance Energy-Efficient Computations
E. Garzón, A. Bedoya, M. Lanuzza, L. Yavits
IEEE Journal on Exploratory Solid-State Computational Devices and Circuits (JxCDC), 2024
BIB ABSTRACT
This paper presents a monolithic 3D associative in-memory processor (M3D AP) that combines emerging non-volatile magnetic tunnel junction (MTJ) technology with massively parallel associative in-memory processing and monolithic 3D integration. The proposed architecture features two monolithic layers, with CMOS logic in the first layer and an MTJ-based content-addressable memory (CAM) array in the second layer. We conduct a thorough analysis of the electrical characteristics of the MTJ-based AP and use analysis results to evaluate the performance and power consumption of the M3D AP. We build a custom cycle-accurate simulator to implement and evaluate the 3D associative matrix multiplication algorithm, highlighting the potential of the M3D AP for accelerating artificial intelligence applications. Overall, we demonstrate the efficacy of M3D AP and show that it holds promise for highperformance and energy-efficient in-memory computing.
-
-
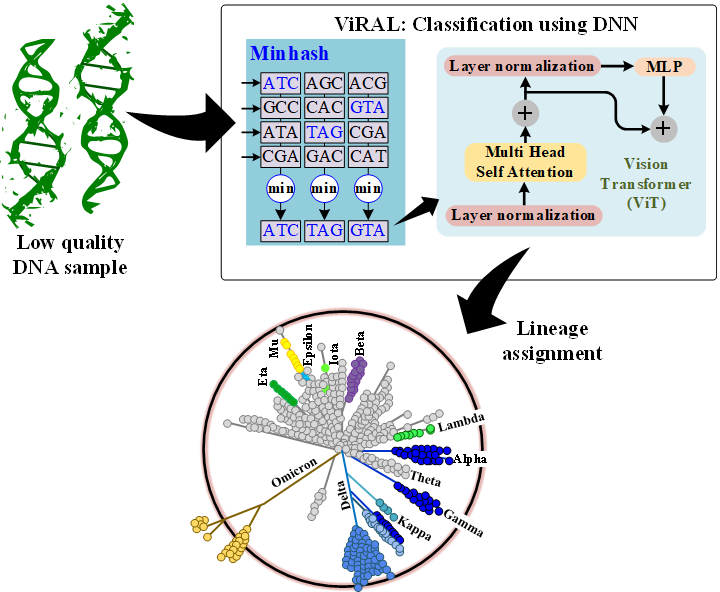
ViRAL: Vision transformer based accelerator for ReAL time lineage assignment of viral pathogens
Z. Jahshan, E. Garzón, L. Yavits
IEEE Access, 2024
BIB ABSTRACT
Real-time genome detection, classification and lineage assignment are critical for efficient tracking of emerging mutations and variants during viral pandemics such as Covid-19. For genomic surveillance to work effectively, each new viral genome sequence must be quickly and accurately associated with an existing viral family (lineage). ViRAL is a hardware-accelerated platform for real-time viral genome lineage assignment based on minhashing and Vision Transformer. Minhashing is a locality sensitive hashing based technique for finding regions of similarity within sequenced genomes. Vision Transformer is a model for image classification that employs a Transformer-like architecture over patches of images. In ViRAL, such image patches are genome fragments extracted from the regions of high similarity. ViRAL is especially efficient in lineage assignment of extremely low quality (or highly ambiguous) genomic data, i.e. when a large fraction of DNA bases are missing in an assembled genome. We implement ViRAL on CPU, GPU and a custom-designed hardware accelerator denoted ACMI. ViRAL assigns newly sequenced SARS-CoV-2 genomes to existing lineages with the top-1 accuracy of 94.2%. The probability of the correct assignment to be found among the five most likely placements generated by ViRAL (top-5 accuracy) is 99.8%. Accelerated ViRAL outperforms the fastest state-of-the-art assignment tools by 69.4X. It also outperforms ViRAL GPU implementation by 19.5X. ViRAL strongly outperforms the state-of-the-art solutions in assigning highly-ambiguous genomes: while state-of-the-art tools fail to assign lineage to genomes with 50% ambiguity, ViRAL achieves 77.6% assignment accuracy. We make ViRAL available to the research community through GitHub.
-
-
OCCAM: An Error Oblivious CAM
Y. Harary, P. Snapir, E. Rechef, E. Garzón, L. Yavits
IEEE Solid-State Circuits Letters (SSC-L), 2024
BIB ABSTRACT
Content addressable memories (CAMs) are widely used in many applications in general purpose computer microarchitecture, networking and domain-specific hardware accelerators. In addition to storing and reading data, CAMs enable simultaneous compare of query datawords with the entire memory content. Similar to SRAM and DRAM, CAMs are prone to errors and faults. While error correcting codes (ECCs) are widely used in DRAM and SRAM, they are not directly applicable in CAM: if a dataword that is supposed to match a query altered due to an error, it will falsely mismatch even if it is ECC-encoded. We propose OCCAM, an error oblivious CAM, which combines ECC and approximate search (matching) to allow tolerating a large and dynamically configurable number of errors. We manufactured the OCCAM silicon prototype using 65-nm commercial process and verified its error tolerance capabilities through silicon measurements. OCCAM tolerates 11% error rate (7 bit errors in each 64-bit memory row) with 100% sensitivity and specificity.
-
-
FASTA: Revisiting Fully Associative Memories in Computer Microarchitecture
E. Garzón, R. Hanhan, M. Lanuzza, A. Teman, L. Yavits
IEEE Access, 2024
BIB ABSTRACT
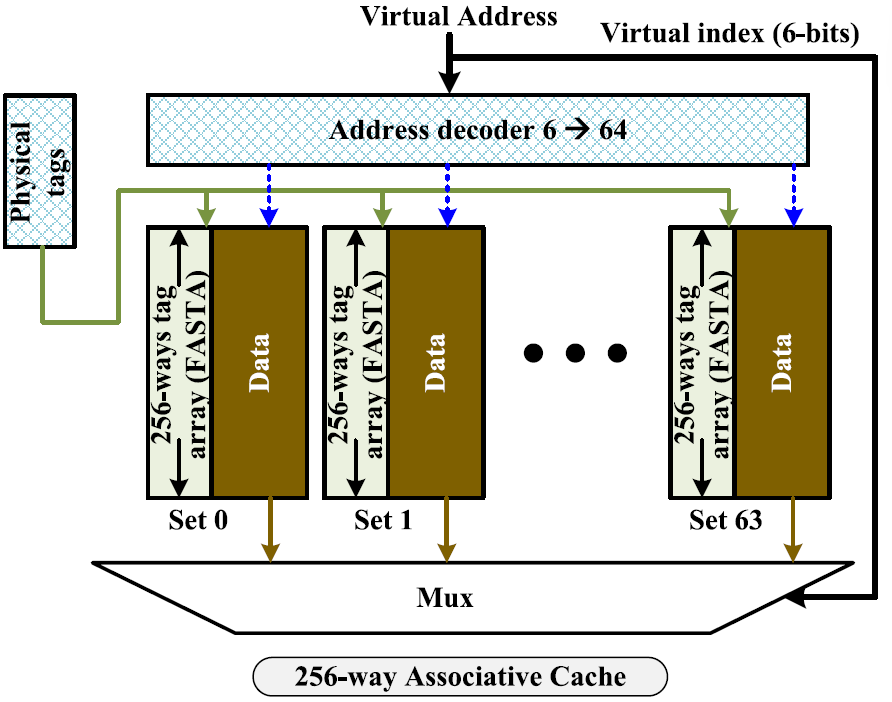
Associative access is widely used in fundamental microarchitectural components, such as caches and TLBs. However, associative (or content addressable) memories (CAMs) have been traditionally considered too large, too energy-hungry, and not scalable, and therefore, have limited use in modern computer microarchitecture. This work revisits these presumptions and proposes an energy-efficient fully-associative tag array (FASTA) architecture, based on a novel complementary CAM (CCAM) bitcell. CCAM offers a full CMOS solution for CAM, removing the need for time- and energy-consuming precharge and combining the speed of NOR CAM and low energy consumption of NAND CAM. While providing better performance and energy consumption, CCAM features a larger area compared to state-of-the-art CAM designs. We further show how FASTA can be used to construct a novel aliasing-free, energy-efficient, Very-Many-Way Associative (VMWA) cache. Circuit-level simulations using 16 nm FinFET technology show that a 128 kB FASTA-based 256-way 8-set associative cache is 28% faster and consumes 88% less energy-per-access than a same sized 8-way (256-set) SRAM based cache, while also providing aliasing-free operation. System-level evaluation performed on the Sniper simulator shows that the VMWA cache exhibits lower Misses Per Kilo Instructions (MPKI) for the majority of benchmarks. Specifically, the 256-way associative cache achieves 17.3%, 11.5%, and 1.2% lower average MPKI for L1, L2, and L3 caches, respectively, compared to a 16-way associative cache. The average IPC improvement for L1, L2, and L3 caches are 1.6%, 1.4%, and 0.2%, respectively.
2023
-
-
AM4: MRAM Crossbar Based CAM/TCAM/ACAM/AP for In-Memory Computing
E. Garzón, M. Lanuzza, A. Teman, L. Yavits
IEEE Journal on Emerging and Selected Topics in Circuits and Systems (JETCAS), 2023
BIB ABSTRACT
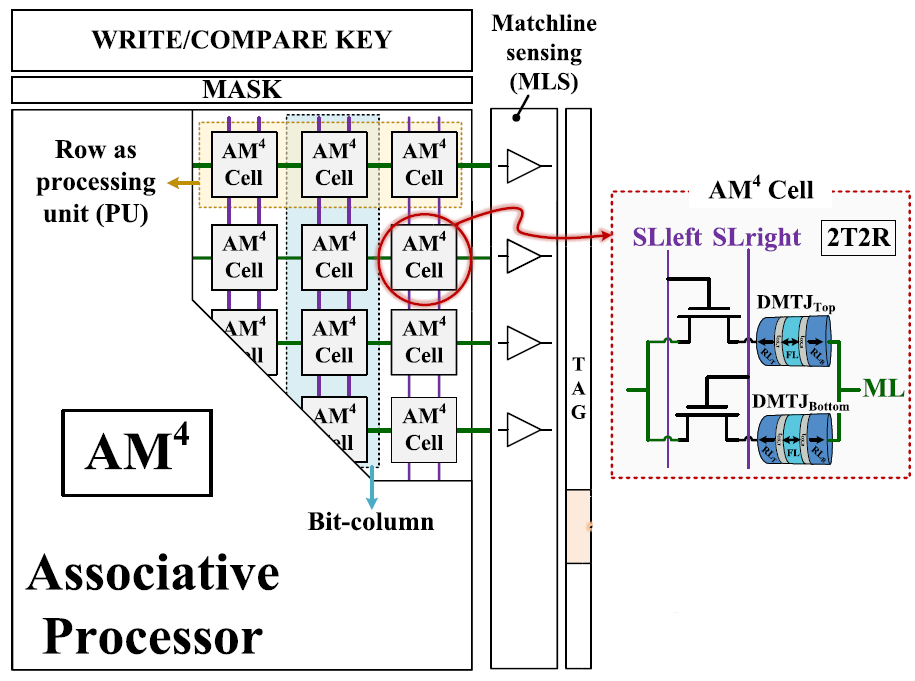
In-memory computing seeks to minimize data movement and alleviate the memory wall by computing in-situ, in the same place that the data is located. One of the key emerging technologies that promises to enable such computing-in-memory is spin-transfer torque magnetic tunnel junction (STT-MTJ). This paper proposes AM4, a combined STT-MTJ-based Content Addressable Memory (CAM), Ternary CAM (TCAM), approximate matching (similarity search) CAM (ACAM), and in-memory Associative Processor (AP) design, inspired by the recently announced Samsung MRAM crossbar. We demonstrate and evaluate the performance and energy-efficiency of the AM4-based AP using a variety of data intensive workloads. We show that an AM4-based AP outperforms state-of-the-art solutions both in performance (with the average speedup of about 10X) and energy-efficiency (by about 60X on average).
-
-
SIMPLY+: A Reliable STT-MRAM-Based Smart Material Implication Architecture for In-Memory Computing
T. Moposita, E. Garzón, R. De Rose, F. Crupi, L. Trojman, A. Vladimirescu, M. Lanuzza
IEEE Access, 2023
BIB ABSTRACT
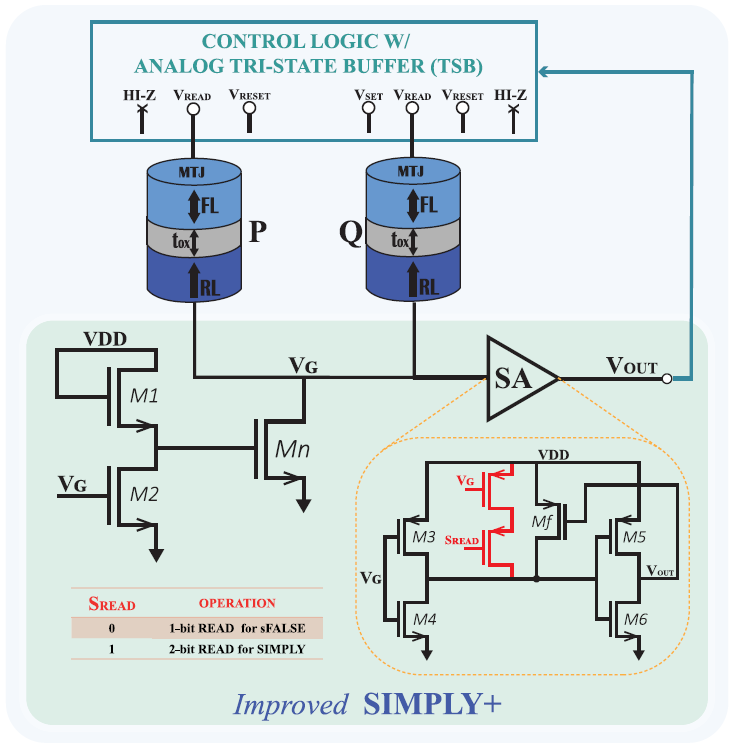
This paper introduces SIMPLY+, an advanced Spin-Transfer Torque Magnetic Random-Access Memory (STT-MRAM)-based Logic-in-Memory (LIM) architecture that evolves from the previously proposed smart material implication (SIMPLY) logic scheme. More specifically, the latter is enhanced by incorporating additional circuitry to enhance the reliability of preliminary read operations. In this study, the proposed architecture is benchmarked against its conventional counterpart. Obtained results show a significant improvement in terms of reliability, i.e., the nominal read margin (RM) by a factor of about 3−4X and accordingly the bit error rate (BER) by more than four orders of magnitude. These improvements come at minimal cost in terms of circuit area and complexity compared to the conventional SIMPLY design. Overall, this research establishes SIMPLY+ as a promising solution for the design of reliable and energy-efficient in-memory computing architectures.
-
-
Voltage-controlled magnetic anisotropy based physical unclonable function
A. Meo, E. Garzón, R. De Rose, G. Finocchio, M. Lanuzza, and M. Carpentieri
Applied Physics Letters (APL), 2023
BIB ABSTRACT
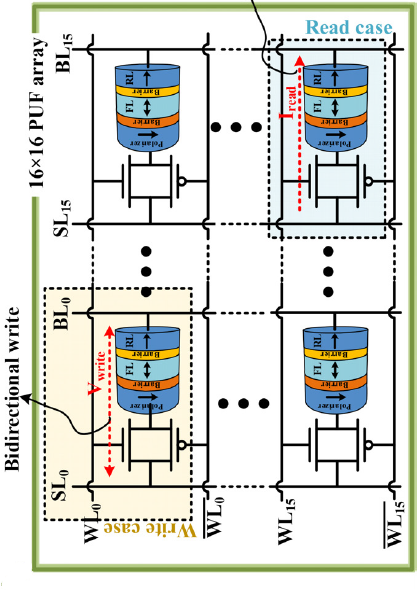
We design a spintronic physical unclonable function (PUF) based on sub-100nm voltage-controlled magnetic anisotropy hybrid magnetic tunnel junctions (VCMA-MTJs). This complementary metal-oxide-semiconductor VCMA-MTJ (CMOS/VCMA-MTJ) PUF architecture was evaluated by combining micromagnetic simulations, Verilog-A modeling, and circuit-level simulations. The PUF architecture, comprising four 16x16 columns arrays, demonstrates effective read and write operations using conventional voltage sensing that are orders of magnitudes lower than previous spintronic-based PUFs. This study proves the potential of the proposed solution in security applications based on hardware authentication.
-
-
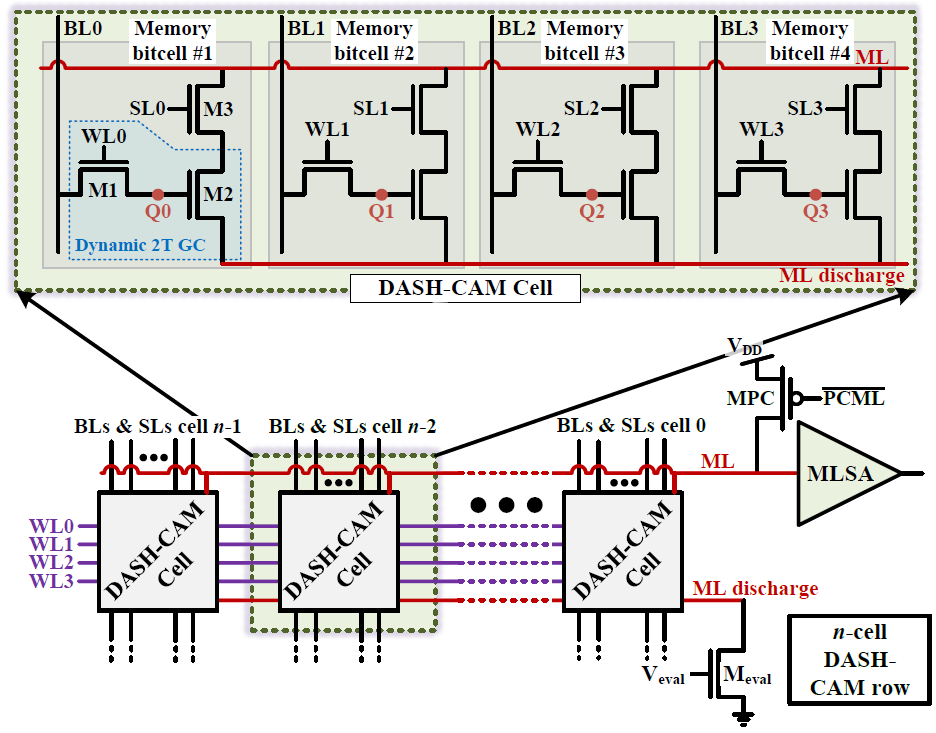
DASH-CAM: Dynamic Approximate SearcH Content Addressable Memory for genome classification
Z. Jahshan, I. Merlin, E. Garzón, L. Yavits
Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2023
BIB ABSTRACT
We propose a novel dynamic storage-based approximate search content addressable memory (DASH-CAM) for computational genomics applications, particularly for identification and classification of viral pathogens of epidemic significance. DASH-CAM provides 5.5 × better density compared to state-of-the-art SRAM-based approximate search CAM. This allows using DASH-CAM as a portable classifier that can be applied to pathogen surveillance in low-quality field settings during pandemics, as well as to pathogen diagnostics at points of care. DASH-CAM approximate search capabilities allow a high level of flexibility when dealing with a variety of industrial sequencers with different error profiles. DASH-CAM achieves up to 30% and 20% higher F1 score when classifying DNA reads with 10% error rate, compared to state-of-the-art DNA classification tools MetaCache-GPU and Kraken2 respectively. Simulated at 1GHz, DASH-CAM provides 1,178× and 1,040× average speedup over MetaCache-GPU and Kraken2 respectively.
-
-
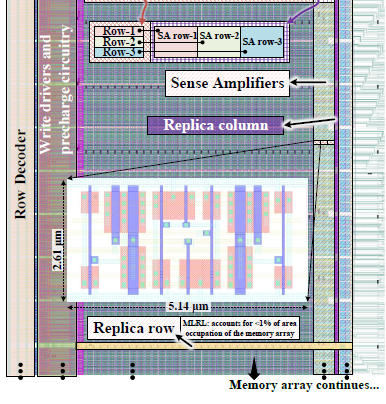
A Low-Complexity Sensing Scheme for Approximate Matching Content-Addressable Memory
E. Garzón, R. Golman, M. Lanuzza, A. Teman, L. Yavits
IEEE Transactions on Circuits and Systems II: Express Briefs (TCAS-II), 2023
BIB ABSTRACT
The need for approximate rather than exact search arises in numerous compare-intensive applications, from networking to computational genomics. This brief presents a novel sensing approach for approximate matching content-addressable memory (CAM) designed to handle large Hamming distances (HDs) between the query pattern and stored data. The proposed matchline sensing scheme (MLSS) employs a replica mechanism and a 12-transistor positive feedback sense amplifier to effectively resolve the approximate match operation. The MLSS was integrated into a 4 kB approximate CAM array and fabricated in a 65 nm CMOS technology. With an overall area footprint of 0.0048 mm2, which includes 512 sense amplifiers and the replica mechanism, the MLSS allows a flexible and dynamic adjustment of the HD tolerance threshold via several design variables. Experimental measurements demonstrate the efficiency of our sensing scheme in tolerating very large HDs with the highest sensitivity.
-
-
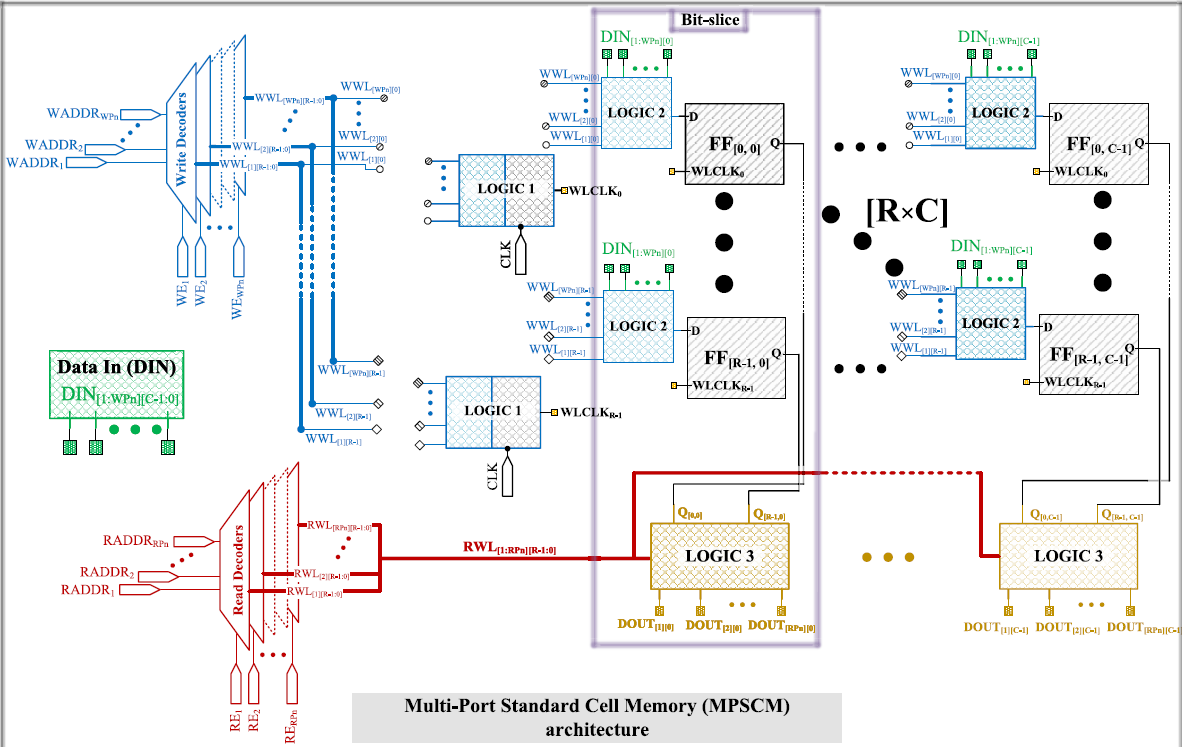
Efficient Implementation of Many-Ported Memories by Using Standard-Cell Memory Approach
H. Marinberg, E. Garzón, T. Noy, M. Lanuzza, and A. Teman
IEEE Access, 2023
BIB ABSTRACT
Multi-ported memories are widely used in many applications, such as for high-speed and high-performance parallel computations. While conventional SRAM-based memory macros are limited in both flexibility (e.g., to accommodate a large number of write inputs and read outputs) and performance, standard cell-based memories are much more flexible and can be parameterized. The physical implementation approaches of the existing tools have great difficulty in dealing with these memories due to the multiplicity of wiring and misunderstanding of the regular structure of these arrays, to the point of inability to converge under certain conditions. This paper presents novel methodologies for the logical and physical implementation of many-ported standard cell memories (MPSCMs). Two methodologies are proposed to replace the standard design flow by controlling and guiding the design tools to improve power consumption, area and performance of these arrays. A commercial 65 nm CMOS technology was used to evaluate and benchmark the two design methodologies on MPSCM macros of different sizes as compared to other equivalent macros designed with standard methodologies and state-of-the-art designs. Physical implementation results show that as compared to a standard RTL approach, the implementation of a 3-write, 5-read port (3W5R) register file with the tightly-controlled methodology leads a 2X increase in placement density along with significant reductions in write power (–66%), read power (–37%) and leakage power (–80%), while also improving the access time (–6%). When considering an extreme case of a many-ported memory with 20-write and 20-read ports (20W/20R), the guided methodology leads to improvements in delay (–13%), write power (–62%), and leakage power (–51%). Both methodologies were implemented within an automation utility based on the “Salamandra” open source netlisting tool, enabling fast and easy migration to additional process nodes and standard cell libraries for generating MPSCMs with various sizes and features.
-
-
STT-MRAM Technology For Energy-Efficient Cryogenic Memory Applications
E. Garzón, L. Yavits, A. Teman, M. Lanuzza
IEEE 14th Latin America Symposium on Circuits and Systems (LASCAS), 2023
BIB ABSTRACT
This work explores non-volatile (NV) embedded memories implemented by spin-transfer torque magnetic random access memories (STT-MRAMs). Our designs are based on state-of-the-art perpendicular magnetic tunnel junctions (MTJs) along with a commercial 65 nm planar CMOS Bulk technology node, both operating at the liquid nitrogen temperature, 77 K. We evaluate the impact of cooling down to 77 K of the STT-MRAMs based on single- and double-barrier MTJ (SMTJ and DMTJ), and DMTJ with the relaxed non-volatility. All NV designs were benchmarked against the six-transistor SRAM (6T-SRAM) baseline. Simulation analysis relies on a 512 kB cache memory operating at 77 K. Overall, results show that the implementation of STT-MRAMs with DMTJ devices, and in particular when using the non-volatility approach by reducing the cross-section area, excel in terms of energy consumption, leading to energy savings for write/read access of about 35%/54%. This saving is obtained while also dissipating less leakage power and requiring a smaller bitcell footprint. Moreover, it presents reduced write latency overhead (as much as 1.9× lower), at the expense of increased read latency and reduced sensing margins of about 1.8× and 88%, respectively. The results suggest that STT-MRAM technology can be a solid alternative for energy-efficient cryogenic memory applications.
-
-
XNOR-Bitcount Operation Exploiting Computing-In-Memory With STT-MRAMs
A. Musello, E. Garzón, M. Lanuzza, L.M. Prócel, and R. Taco
IEEE Transactions on Circuits and Systems II: Express Briefs (TCAS-II), 2023
BIB ABSTRACT
This brief presents an energy-efficient and high-performance XNOR-bitcount architecture exploiting the benefits of computing-in-memory (CiM) and unique properties of spin-transfer torque magnetic RAM (STT-MRAM) based on double-barrier magnetic tunnel junctions (DMTJs). Our work proposes hardware and algorithmic optimizations, benchmarked against a state-of-the-art CiM-based XNOR-bitcount design. Simulation results show that our hardware optimization reduces the storage requirement (–50%) for each XNOR-bitcount operation. The proposed algorithmic optimization improves execution time and energy consumption by about 30% (78%) and 26% (85%), respectively, for single (5 sequential) 9-bit XNOR-bitcount operations. As a case study, our solution is demonstrated for shape analysis using bit-quads.
-
-
A Low-Energy DMTJ-Based Ternary Content- Addressable Memory With Reliable Sub-Nanosecond Search Operation
E. Garzón, L. Yavits, G. Finocchio, M. Carpentieri, A. Teman, M. Lanuzza
IEEE Access, 2023
BIB ABSTRACT
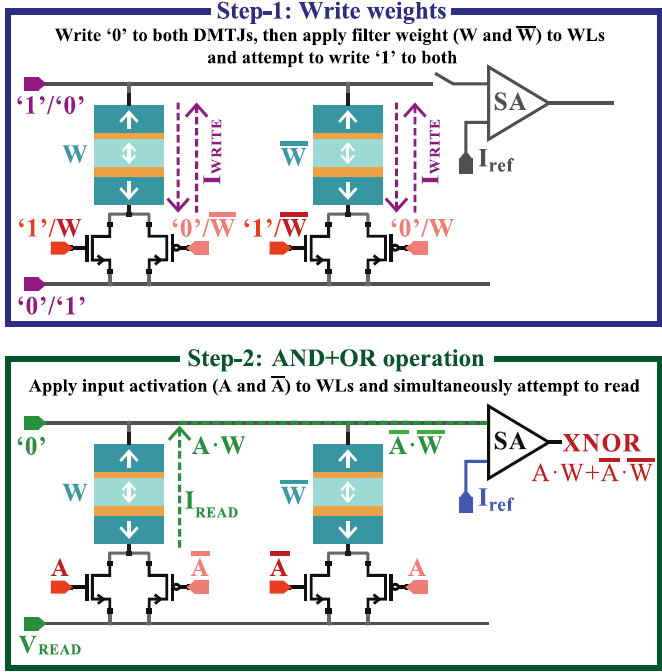
In this paper, we propose an energy-efficient, reliable, hybrid, 10-transistor/2-Double-Barrier-Magnetic-Tunnel-Junction (10T2DMTJ) non-volatile (NV) ternary content-addressable memory (TCAM) with sub-nanosecond search operation. Our cell design relies on low-energy-demanding MTJs organized in a low-complexity voltage-divider-based circuit along with a simple dynamic logic CMOS matching network, which improves the search reliability. The proposed NV-TCAM was designed in 28 nm FDSOI process and evaluated under exhaustive Monte Carlo simulations. When compared to the best previous proposed NV-TCAMs, our solution achieves lower search error rate (3.8X) and lower write and search energy (–73% and–79%, respectively), while also exhibiting smaller area footprint (–74%). Such benefits are achieved at the expense of reduced search speed.
-
-
Efficiency of Double-Barrier Magnetic Tunnel Junction-Based Digital eNVM Array for Neuro-Inspired Computing
T. Moposita, E. Garzón, F. Crupi, L. Trojman, A. Vladimirescu, M. Lanuzza
IEEE Transactions on Circuits and Systems II: Express Briefs (TCAS-II), 2023
BIB ABSTRACT
This brief deals with the impact of spin-transfer torque magnetic random access memory (STT-MRAM) cell based on double-barrier magnetic tunnel junction (DMTJ) on the performance of a two-layer multilayer perceptron (MLP) neural network. The DMTJ-based cell is benchmarked against the conventional single-barrier MTJ (SMTJ) counterpart by means of a comprehensive evaluation carried out through a state-of-the-art device-to-algorithm simulation framework. The benchmark is based on the MNIST handwritten dataset, Verilog-A MTJ compact models developed by our group, and 0.8 V FinFET technology. Our results point out that the use of DMTJ-based STT-MRAM cells to implement digital embedded non-volatile memory (eNVM) synaptic core allows write/read energy and latency improvements of about 53%/61% and 66%/17%, respectively, as compared to the SMTJ-based equivalent design. This is achieved by ensuring a reduced area footprint and a learning accuracy of about 91%. Such results make the DMTJ-based STT-MRAM cell a good eNVM option for neuro-inspired computing.
-
-
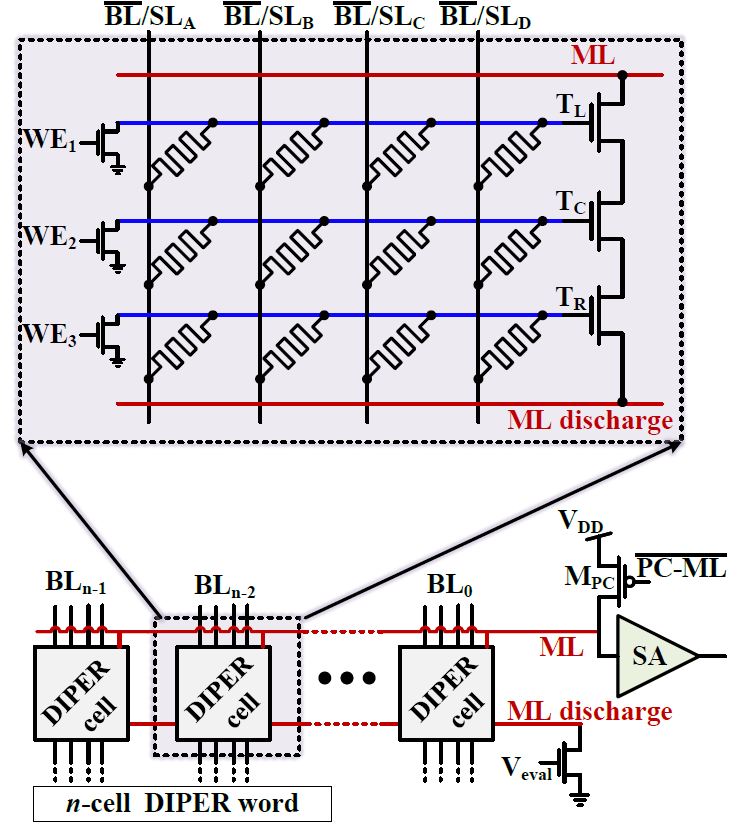
DIPER: Detection and Identification of Pathogens using Edit distance-tolerant Resistive CAM
I. Merlin, E. Garzón, A. Fish, L. Yavits
IEEE Transactions on Computers (TC), 2023
BIB ABSTRACT
We propose a novel resistive edit distance-tolerant content addressable memory for computational genomics applications, particularly for detection and identification of pathogens of pandemic importance. Unlike state-of-the-art approximate search solutions that tolerate small number of replacements between the query pattern and the stored data, DIPER tolerates insertions and deletions, ubiquitous in genomics. DIPER achieves up to 1.7× higher F1 score for high-quality DNA reads and up to 6.2× higher F1 score for DNA reads with 15% error rate, compared to state-of-the-art DNA classification tool Kraken2. Simulated at 500MHz, DIPER provides 910× average speedup over Kraken2.
-
-
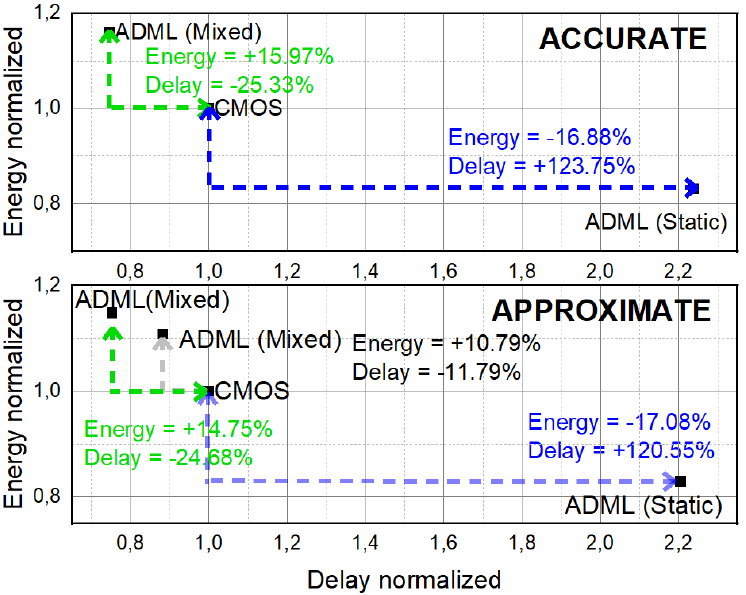
Exploiting Dual Mode Logic for Approximate Computing
C. Mosquera, E. Garzón, L.M. Prócel
IEEE Seventh Ecuador Technical Chapters Meeting (ETCM), 2023
BIB ABSTRACT
The unique ability of dual-mode logic (DML) to self-adapt to computational needs by providing high speed and/or low-energy consumption is demonstrated for the first time for exact or approximate operations suitable for both error-resilient and exact applications. At the gate level, the DML design offers the possibility to operate either in the static mode to save energy or in the dynamic mode to increase speed, albeit with higher delay or energy consumption, respectively. In this paper, these two operation modes of the DML gates are optimally managed by a self-adjustment mechanism to increase speed or reduce the energy at run time, while changing the design accuracy. As a test case, a DML Carry Look Ahead adder (CLA) based in Dual Mode Logic (DML) that can operate in exact and approximate mode with the same frequency has been proposed. Through comparisons with CMOS-based alternative at various operating voltages, the advantages of the ADMLCLA are showcased. In static mode, the ADML-CLA presents less energy consumption of about 16% to 21%. In mixed mode, the ADML-CLA achieves delay reduction of 21% to 25%. The effectiveness of the controller in saving energy is demonstrated, with the ADML-CLA consuming less energy than CMOS when static signals are prevalent. Monte Carlo simulations highlight the lower average delay and deviation of the ADML-CLA compared to CMOS. Evaluation at a nominal voltage of 0.4V shows that the ADML (mixed) outperforms CMOS in terms of energy-delay product (EDP) in both exact and approximate modes.
-
-
Approximate Content-Addressable Memories: A Review
E. Garzón, L. Yavits, A. Teman, M. Lanuzza
Chips, 2023
BIB ABSTRACT
Content-addressable memory (CAM) has been part of the memory market for more than five decades. CAM can carry out a single clock cycle lookup based on the content rather than an address. Thanks to this attractive feature, CAM is utilized in memory systems where a high-speed content lookup technique is required. However, typical CAM applications only support exact matching, as opposed to approximate matching, where a certain Hamming distance (several mismatching characters between a query pattern and the dataset stored in CAM) needs to be tolerated. Recent interest in approximate search has led to the development of new CAM-based alternatives, accelerating the processing of large data workloads in the realm of big data, genomics, and other data-intensive applications. In this review, we provide an overview of approximate CAM and describe its current and potential applications that would benefit from approximate search computing.
2022
-
-
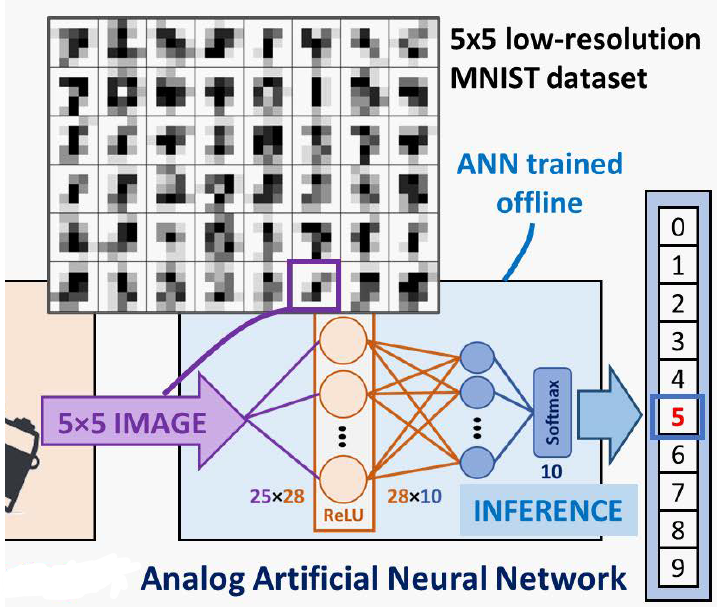
All-Analog Silicon Integration of Image Sensor and Neural Computing Engine for Image Classification
B. Zambrano, S. Strangio, T. Rizzo, E. Garzón, M. Lanuzza, G. Iannaccone
IEEE Access, 2022
BIB ABSTRACT
We have designed a fully-integrated analog CMOS cognitive image sensor based on a two-layer artificial neural network and targeted to low-resolution image classification. We have used a single poly 180 nm CMOS process technology, which includes process modules for realizing the building blocks of the CMOS image sensor. Our design includes all the analog sub-circuits required to perform the cognitive sensing task, from image sensing to output classification decision. The weights of the network are stored in single-poly floating-gate memory cells, using a single transistor per analog weight. This enables the classifier to be intrinsically reconfigurable, and to be trained for various classification problems, based on low-resolution images. As a case study, the classifier capability is tested using a low-resolution version of the MNIST dataset of handwritten digits. The circuit exhibits a classification accuracy of 87.8%, that is comparable to an equivalent software implementation operating in the digital domain with floating point data precision, with an average energy consumption of 6 nJ per inference, a latency of 22.5 μs and a throughput of up to 133.3 thousand inferences per second.
-
-
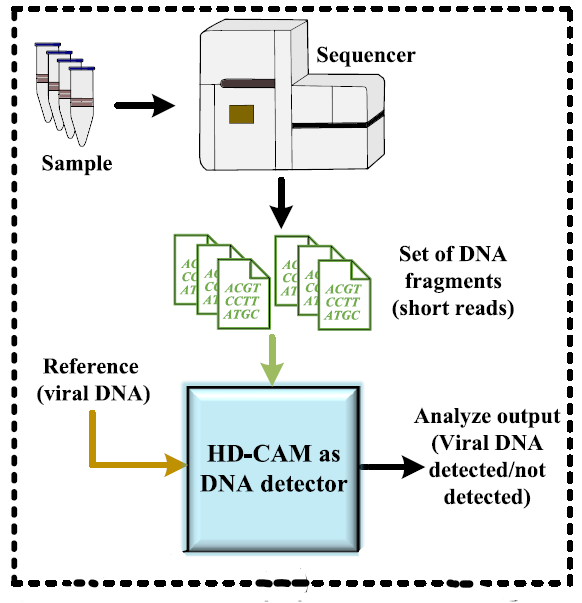
Hamming Distance Tolerant Content-Addressable Memory (HD-CAM) for DNA Classification
E. Garzón, R. Golman, Z. Jahshan, R. Hanhan, N. Vinshtok-Melnik, M. Lanuzza, A. Teman, L. Yavits
IEEE Access, 2022
BIB ABSTRACT
This paper proposes a novel Hamming distance tolerant content-addressable memory (HD-CAM) for energy-efficient in-memory approximate matching applications. HD-CAM exploits NOR-type based static associative memory bitcells, where we add circuitry to enable approximate search with programmable tolerance. HD-CAM implements approximate search using matchline charge redistribution rather than its rise or fall time, frequently employed in state-of-the-art solutions. HD-CAM was designed in a 65 nm 1.2 V CMOS technology and evaluated through extensive Monte Carlo simulations. Our analysis shows that HD-CAM supports robust operation under significant process variations and changes in the design parameters, enabling a wide range of mismatch threshold (tolerable Hamming distance) levels and pattern lengths. HD-CAM was functionally evaluated for virus DNA classification, which makes HD-CAM suitable for hardware acceleration of genomic surveillance of viral outbreaks, such as Covid-19 pandemics.
-
-
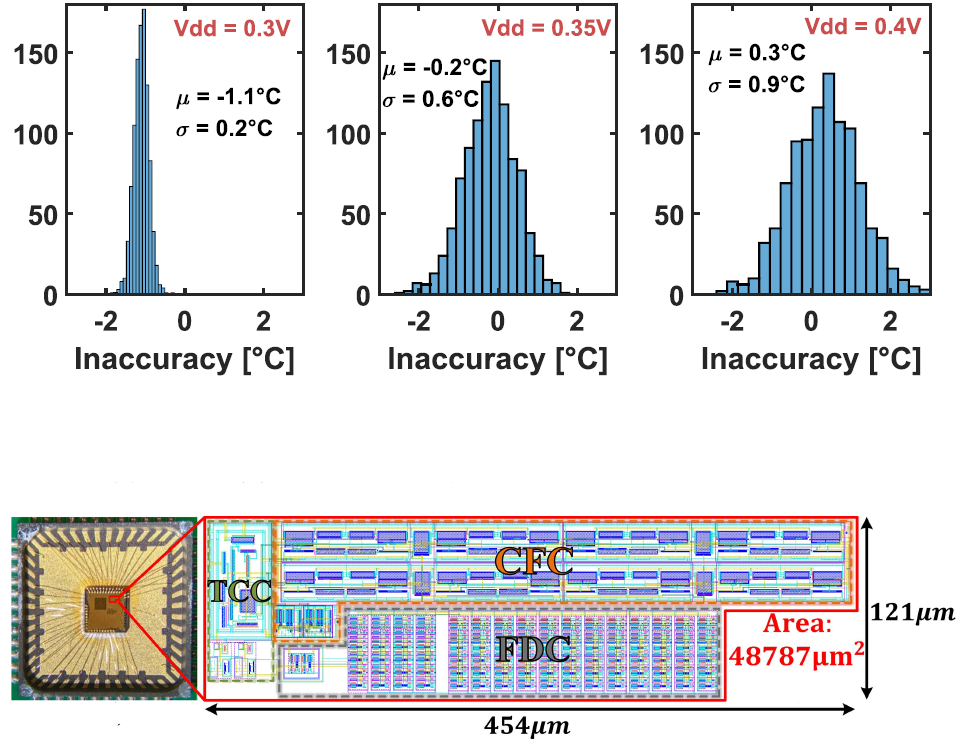
A 0.6V–1.8V Compact Temperature Sensor With 0.24°C Resolution, ±1.4°C Inaccuracy and 1.06nJ per Conversion
B. Zambrano, E. Garzón, S. Strangio, G. Iannaccone, M. Lanuzza
IEEE Sensors Journal, 2022
BIB ABSTRACT
This paper presents a fully-integrated CMOS temperature sensor for densely-distributed thermal monitoring in systems on chip supporting dynamic voltage and frequency scaling. The sensor front-end exploits a sub-threshold PMOS-based circuit to convert the local temperature into two biasing currents. These are then used to define two oscillation frequencies, whose ratio is proportional to absolute-temperature. Finally, the sensor back-end translates such frequency ratio into the digital temperature code. Thanks to its low-complexity architecture, the proposed design achieves a very compact footprint along with low-power consumption and high accuracy in a wide temperature range. Moreover, thanks to a simple embedded line regulation mechanism, our sensor supports voltage-scalability. The design was prototyped in a 180nm CMOS technology with a 0°C−100°C temperature detection range, a very wide supply voltage operating range from 0.6V up to 1.8V and very small silicon area occupation of just 0.021mm2 . Experimental measurements performed on 20 test chips have shown very competitive figures of merit, including a resolution of 0.24°C, an inaccuracy of ±1.4°C, a sampling rate of about 1.5kHz and an energy per conversion of 1.06nJ at 30°C.
-
-
EDAM: Edit distance tolerant approximate matching content addressable memory
R. Hanhan, E. Garzón, Z. Jahshan, A. Teman, M. Lanuzza, L. Yavits
Proceedings of the 49th Annual International Symposium on Computer Architecture (ISCA), 2022
BIB ABSTRACT
We propose a novel edit distance-tolerant content addressable memory (EDAM) for energy-efficient approximate search applications. Unlike state-of-the-art approximate search solutions that tolerate certain Hamming distance between the query pattern and the stored data, EDAM tolerates edit distance, which makes it especially efficient in applications such as text processing and genome analysis. EDAM was designed using a commercial 65 nm 1.2 V CMOS technology and evaluated through extensive Monte Carlo simulations, while considering different process corners. Simulation results show that EDAM can achieve robust approximate search operation with a wide range of edit distance threshold levels. EDAM is functionally evaluated as a pathogen DNA detection and classification accelerator. EDAM achieves up to 1.7x higher F1 score for high-quality DNA reads and up to 19.55x higher F1 score for DNA reads with 15% error rate, compared to state-of-the-art DNA classification tool Kraken2. Simulated at 667 MHz, EDAM provides 1, 214× average speedup over Kraken2. This makes EDAM suitable for hardware acceleration of genomic surveillance of outbreaks, such as the ongoing Covid-19 pandemic.
-
-
Voltage and technology scaling of DMTJ-based STT-MRAMs for energy-efficient embedded memories
E. Garzón, R. Taco, L.M. Prócel, L. Trojman, M. Lanuzza
IEEE 13th Latin America Symposium on Circuits and System (LASCAS), 2022
BIB ABSTRACT
This work presents energy advantages allowed by the technology and voltage scaling of spin-transfer torque mag-netic random access memories (STT-MRAMs) based on perpen-dicular double-barrier magnetic tunnel junction (DMTJ), with two reference layers. DMTJ is benchmarked against the single-barrier MTJ (SMTJ) -based alternative, and a comprehensive evaluation is carried out through a cross-layer simulation frame-work, considering state-of-the-art Verilog-A based SMTJ and DMTJ compact models, along with a 0.8V FinFET technology. Simulation results show that, thanks to the lower voltage op-erating point, DMTJ-based STT-MRAM allows energy savings for write/read operations of about 38%/45%, as compared to its SMTJ-based counterpart. Moreover, scaling from the 28 nm down to the 20 nm node, the DMTJ-based memory cell improves write/read energy of about 29%/33% at the expense of longer access times.
-
-
Performance benchmarking of TFET and FinFET digital circuits from a synthesis-based perspective
M. Rendón, C. Cao, K. Landázuri, E. Garzón, L.M Prócel, R. Taco
Electronics, 2022
BIB ABSTRACT
Miniaturization and portable devices have reshaped the electronic device landscape, emphasizing the importance of high performance while maintaining energy efficiency to ensure long battery life. FinFET and Tunnel-FET technologies have emerged as attractive alternatives to overcome the limitations of supply voltage scaling for ultra-low power applications. This work compares the performance of 10 nm FinFET- and TFET-based digital circuits from basic logic gates up to an 8k gates low-power microprocessor. When compared with their FinFET-based counterparts, the TFET-based logic gates have lower leakage power when operated below 300 mV, show higher input capacitance, and exhibit a reduced propagation delay under different fan-in and fan-out conditions. Our comparative study was extended to the synthesis of an MSP-430 microprocessor through standard cell libraries built particularly for this work. It is demonstrated that the TFET-based synthesized circuits operating at ultra-low voltages achieve a higher performance in terms of speed at the cost of increased power consumption. When the speed requirements are relaxed, the TFET-based designs are the most energy-efficient alternative. It is concluded that the TFET is an optimal solution for ultra-low voltage design.
-
-
AIDA: Associative In-Memory Deep Learning Accelerator
E. Garzón, A. Teman, M. Lanuzza, L. Yavits
IEEE Micro, 2022
BIB ABSTRACT
This work presents an associative in-memory deep learning processor (AIDA) for edge devices. An associative processor is a massively parallel non-von Neumann accelerator that uses memory cells for computing; the bulk of data is never transferred outside the memory arrays for external processing. AIDA utilizes a dynamic content addressable memory for both data storage and processing, and benefits from sparsity and limited arithmetic precision, typical in modern deep neural networks. The novel in-data processing implementation designed for the AIDA accelerator achieves a speedup of 270X over an advanced central processing unit at more than three orders-of-magnitude better energy efficiency.
-
-
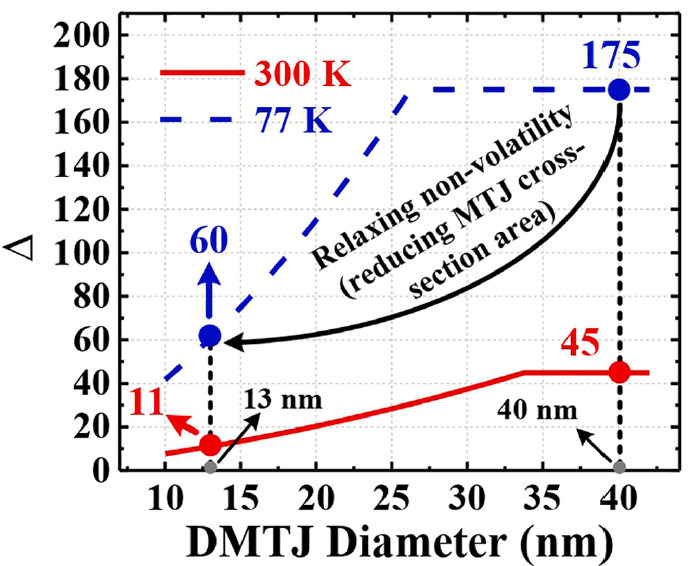
Adjusting thermal stability in double-barrier MTJ for energy improvement in cryogenic STT-MRAMs
E. Garzón, R. De Rose, F. Crupi, L. Trojman, A. Teman, M. Lanuzza
Solid-State Electronics (SSE), 2022
BIB ABSTRACT
This paper investigates the impact of thermal stability relaxation in double-barrier magnetic tunnel junctions (DMTJs) for energy-efficient spin-transfer torque magnetic random access memories (STT-MRAMs) operating at the liquid nitrogen boiling point (77 K). Our study is carried out through a macrospin-based Verilog-A compact model of DMTJ, along with a 65 nm commercial process design kit (PDK) calibrated down to 77 K under silicon measurements. Comprehensive bitcell-level electrical characterization is used to estimate the energy/latency per operation and leakage power at the memory architecture-level. As a main result of our analysis, we show that energy-efficient small-to-large embedded memories can be obtained by significantly relaxing the non-volatility requirement of DMTJ devices at room temperature (i.e., by reducing the cross-section area), while maintaining the typical 10-years retention time at cryogenic temperatures. This makes DMTJ-based STT-MRAM operating at 77 K more energy-efficient than six-transistors static random-access memory (6T-SRAM) under both read and write accesses (−56% and −37% on average, respectively). Obtained results thus prove that DMTJ-based STT-MRAM with relaxed retention time is a promising alternative for the realization of reliable and energy-efficient embedded memories operating at cryogenic temperatures.
-

-
A RISC-V-based research platform for rapid design cycle
E. Garzón, R. Golman, O. Harel, T. Noy, U. Kra, A. Pollock, S. Yuzhaninov, Y. Shoshan, Y. Rudin, Y. Weitzman, M. Lanuzza, A. Teman
IEEE International Symposium on Circuits and Systems (ISCAS), 2022
BIB ABSTRACT
This work proposes a novel platform for bringing a project from the concept to the tapeout stage in a short amount of time. An open-source and extendable RISC-V architecture is exploited to build a small area footprint core. This leads the research platform to be flexible in terms of design integration, while also allowing fast design cycles of research chips.
-
-
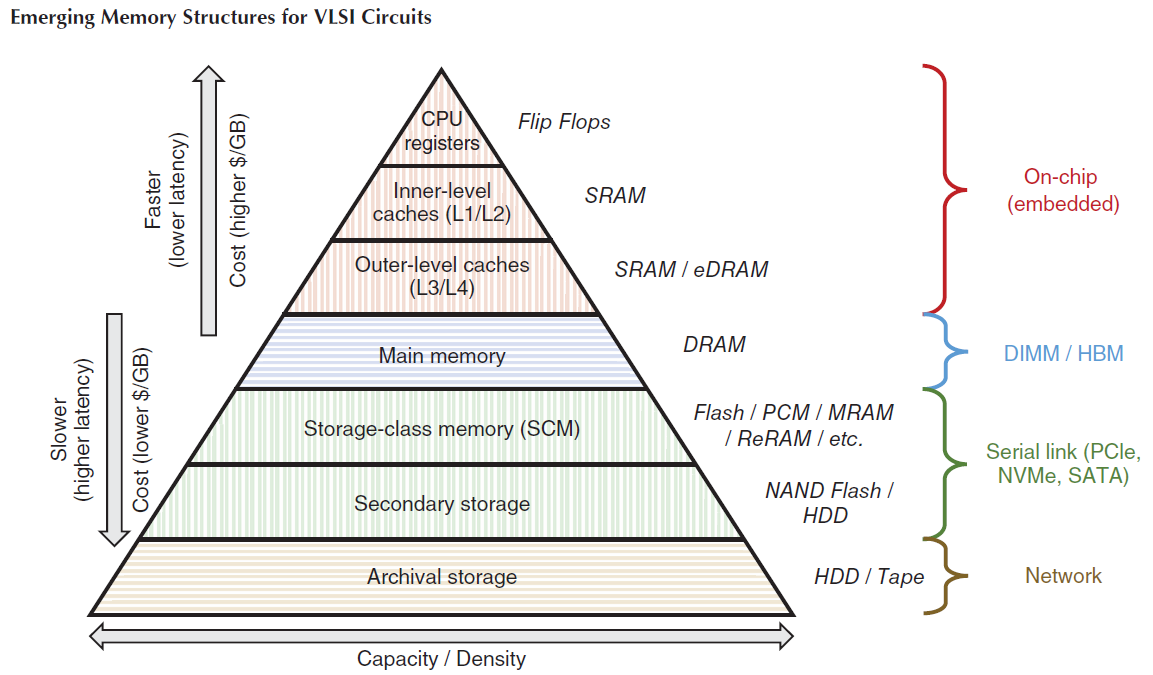
Emerging Memory Structures for VLSI Circuits
E. Garzón, L. Yavits, M. Lanuzza, A. Teman
Wiley Encyclopedia of Electrical and Electronics Engineering (EEEE), 2022
BIB ABSTRACT
Ever since the emergence of the electrical computer and the Von Neumann model, computer architects have adhered to a well-structured hierarchy of memory solutions, clearly trading off performance and capacity with cost. The ubiquitous memory technologies, dominated by SRAM, DRAM, Flash, and magnetic hard disks, are each situated in a well-defined location within this hierarchy. However, as processes have scaled into deep nanometer feature sizes and the demand for larger capacities and bandwidths increases, these traditional options face tough challenges and may be limited in their ability to continue to provide the new requirements. New technologies, such as phase change memory (PCM), magnetic RAM (MRAM), and resistive RAM (RRAM), have been researched and developed over the recent past in an attempt to meet these demands and replace some or all of the traditional technologies. In this article, the primary technologies are overviewed, including those that currently fill the memory hierarchy pyramid, the primary candidates to join or replace them in the near-term, and a number of newer candidates that may arise as legitimate solutions in the farther term. In addition, an overview of the current state of processing within the emerging memory technologies is provided, as an attempt to break free of the traditional Von Neumann paradigm to overcome the energy and performance bottlenecks in modern systems.
-
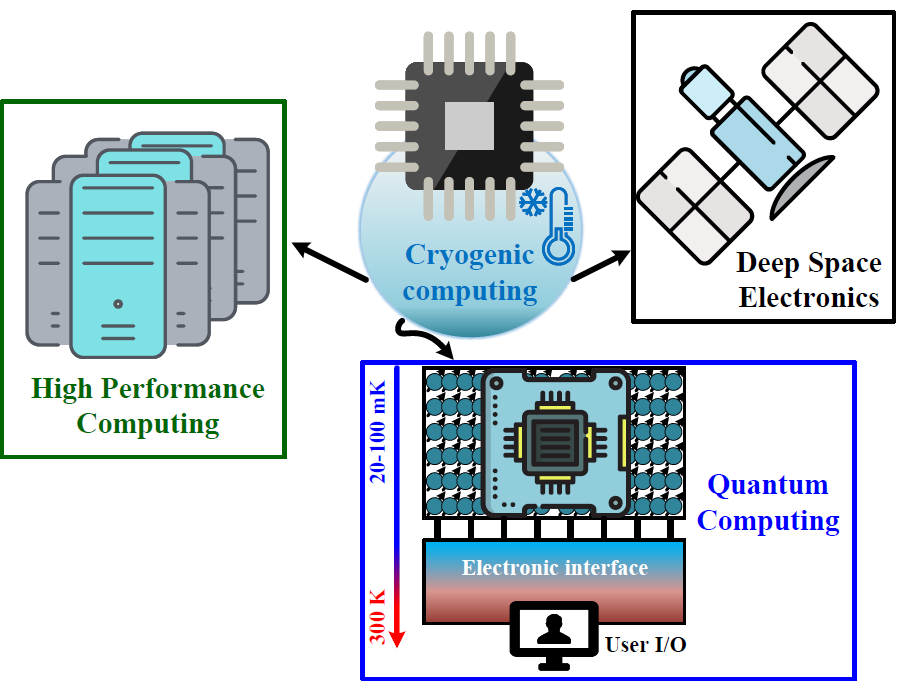
-
Embedded memories for cryogenic applications
E. Garzón, A. Teman, M. Lanuzza
Electronics, 2022
BIB ABSTRACT
The ever-growing interest in cryogenic applications has prompted the investigation for energy-efficient and high-density memory technologies that are able to operate efficiently at extremely low temperatures. This work analyzes three appealing embedded memory technologies under cooling—from room temperature (300 K) down to cryogenic levels (77 K). As the temperature goes down to 77 K, six-transistor static random-access memory (6T-SRAM) presents slight improvements for static noise margin (SNM) during hold and read operations, while suffering from lower (−16%) write SNM. Gain-cell embedded DRAM (GC-eDRAM) shows significant benefits under these conditions, with read voltage margins and data retention time improved by about 2× and 900×, respectively. Non-volatile spin-transfer torque magnetic random access memory (STT-MRAM) based on single- or double-barrier magnetic tunnel junctions (MTJs) exhibit higher read voltage sensing margins (36% and 48%, respectively), at the cost of longer write access time (1.45X and 2.1X, respectively). The above characteristics make the considered memory technologies to be attractive candidates not only for high-performance computing, but also enable the possibility to bridge the gap from room-temperature to the realm of cryogenic applications that operate down to liquid helium temperatures and below.
-
-
A 0.05 mm2, 350 mV, 14 nW Fully-Integrated Temperature Sensor in 180-nm CMOS
B. Zambrano, E. Garzón, S. Strangio, F. Crupi, M. Lanuzza
IEEE Transactions on Circuits and Systems II: Express Brief (TCAS-II), 2022
BIB ABSTRACT
In this brief, we present a fully-integrated ring-oscillator based CMOS temperature sensor for Internet-of-Things. Our design relies on a low-complexity PMOS-based sensing circuit to convert temperature into two sub-threshold biasing currents. These are then used to define two oscillation frequencies, whose ratio increases linearly with the temperature. Change in the frequency ratio is finally translated into a digital output code. The proposed sensor was fabricated in 180-nm CMOS technology. When powered at 350 mV, it can achieve an energy/conversion of 0.46 nJ in a conversion time of 33 ms. Moreover, it exhibits a measurement resolution of 0.27°C and a resolution figure-of-merit as low as 0.034 nJ°C^2.
2021
-
-
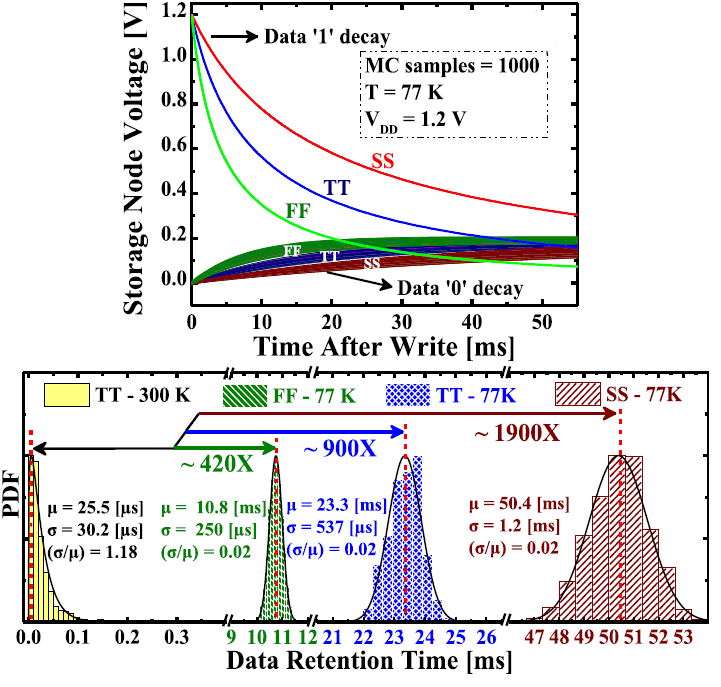
Gain-Cell Embedded DRAM Under Cryogenic Operation—A First Study
E. Garzón, Y. Greenblatt, O.Harel, M. Lanuzza, A. Teman
IEEE Transactions on Very Large Scale Integration (VLSI) Systems (TVLSI), 2021
BIB ABSTRACT
Operating circuits under cryogenic conditions is effective for a large spectrum of applications. However, the refrigeration requirement for the cooling of cryogenic systems introduces serious issues in terms of power dissipation. Gain-cell embedded dynamic random access memory (GC-eDRAM) is a low-area, logic-compatible embedded memory alternative to static random access memory (SRAM), which has the potential to provide ultralow-power operation under cryogenic conditions due to the lower leakages at these temperatures. In this article, we present the first comparative design exploration of GC-eDRAM under cryogenic conditions performed with transistor models characterized based on actual silicon measurements under temperatures as low as 77 K. Our study shows that the two-transistor (2T)-based GC-eDRAM configurations turn out to be the best solutions for very low-temperature operation. In particular, the 2T mixed GC-eDRAM configurations allow read sensing margin improvements (up to 99%) within the 2T-based configurations while at the same time excel in terms of data retention time (+44%) and power consumption (-27%) when compared to more complex GC-eDRAM topologies. Moreover, even better improvements in terms of area (-73%), leakage power (-97%), retention power (-76%), and energy (-66%) are observed when compared to conventional 6T-SRAM.
-
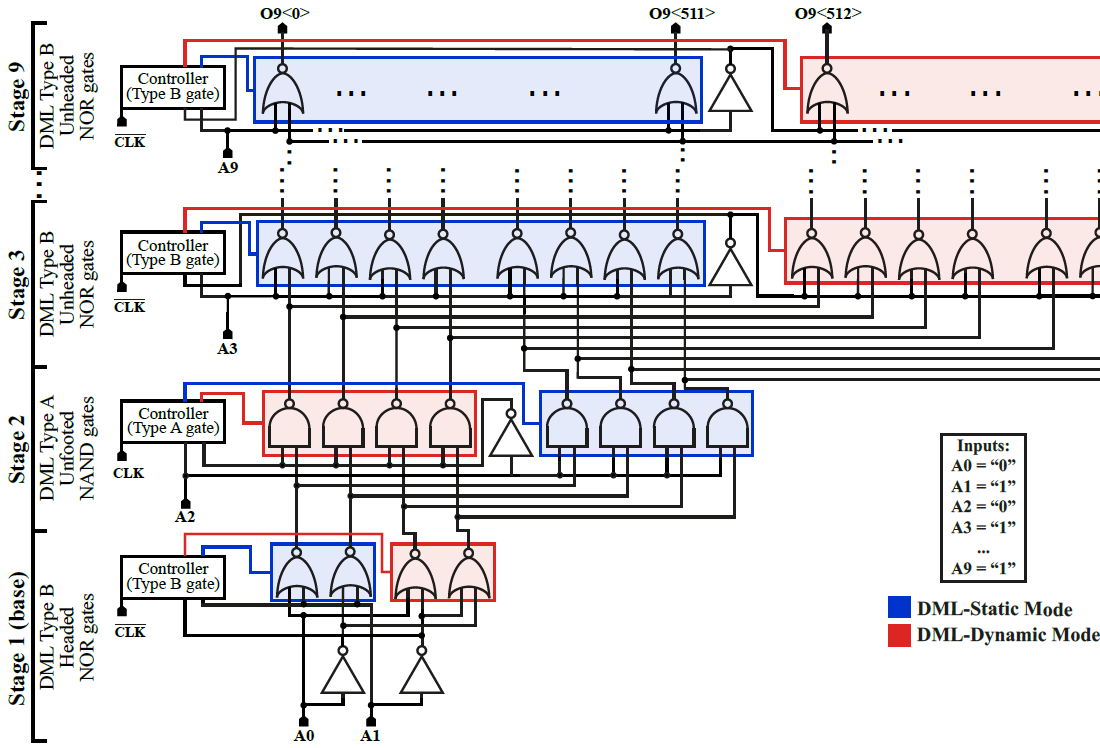
-
Energy efficient self-adaptive Dual Mode Logic address decoder
K. Vicuña, C. Mosquera, A. Musello, S. Benedictis, M. Rendón, E. Garzón, L.M Prócel, L. Trojman, R. Taco
Electronics, 2021
BIB ABSTRACT
This paper presents a 1024-bit self-adaptive memory address decoder based on Dual Mode Logic (DML) design style to allow working in two modes of operation (i.e., dynamic for high-performance and static for energy-saving). The main novelty of this work relies on the design of a controlling mechanism that mixes both of these modes of operation to simultaneously benefit from their inherent advantages. When performance is the primary target, the mixed operating mode is enabled, and the self-adjustment mechanism identifies at run time the logic gates that have to work in the energy-efficient mode (i.e., static mode), while those belonging to the critical path operate in the faster dynamic mode. Moreover, our address decoder can run in the fully static mode for the lowest energy consumption when speed is not a primary concern. A 65 nm CMOS technology was exploited to simulate and compare our solution with other logically equivalent dynamic and static designs. Operated in the mixed mode, the proposed circuit exhibits negligible speed reduction (8.7%) in comparison with a dynamic logic based design while presenting significantly reduced energy consumption (28%). On the contrary, further energy is saved (29%) with respect to conventional logic styles when our design runs in its energy efficient mode.
-
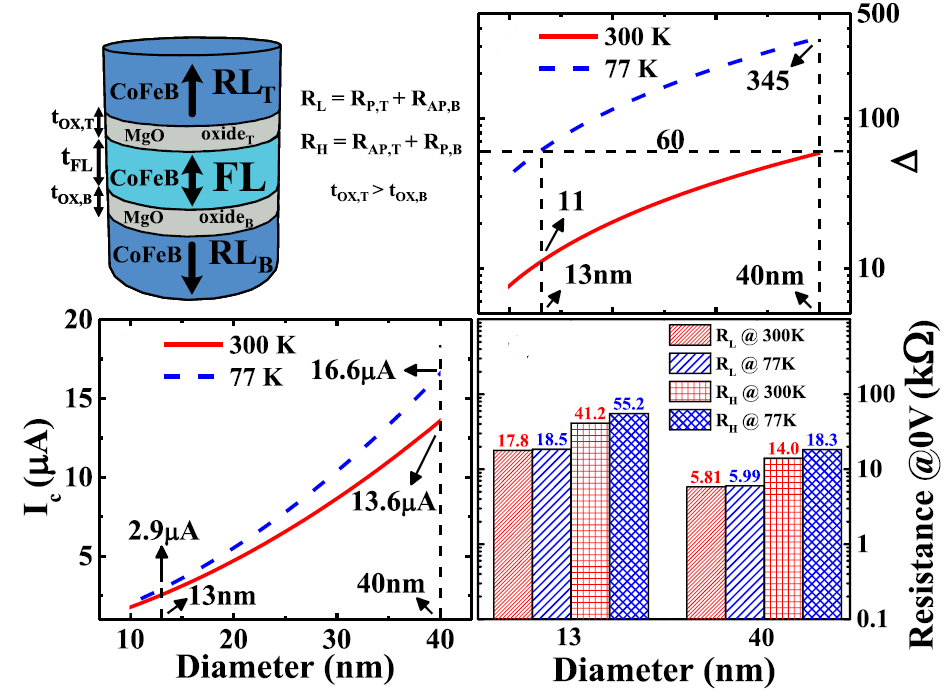
-
Relaxing non-volatility for energy-efficient DMTJ based cryogenic STT-MRAM
E. Garzón, R. De Rose, F. Crupi, L. Trojman, A. Teman, M. Lanuzza
Solid-State Electronics (SSE), 2021
BIB ABSTRACT
Spin-transfer torque magnetic random-access memory (STT-MRAM) is considered as a premiere candidate for replacing conventional six-transistors static random-access memory (6T-SRAM) in processor caches. This paper explores STT-MRAMs based on double-barrier magnetic tunnel junction with two reference layers (DMTJ), while operating at cryogenic temperatures (77 K). To deal with large dynamc energy and long latency of write operation, we suggest to significantly relax the non-volatility requirement of DMTJ devices at room temperature by reducing the cross-section area, while maintaining the typical 10-years retention time at the target operating temperature. This leads the cryogenic DMTJ-based STT-MRAM to be more energy-efficient than its 6T-SRAM counterpart under both read and write operations, while exhibiting smaller area footprint.
-
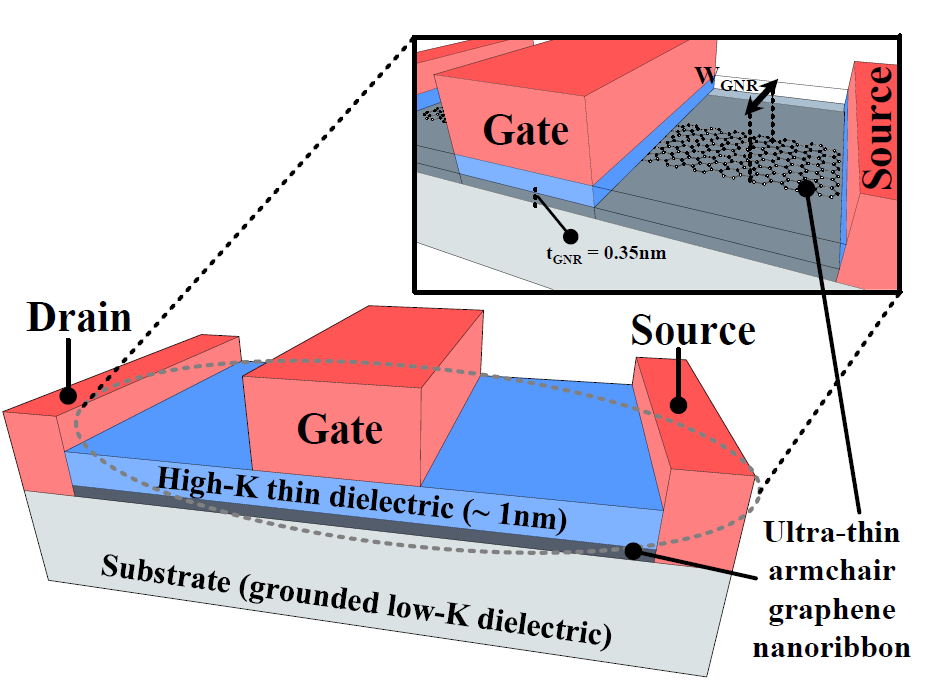
-
Quantum capacitance transient phenomena in high-k dielectric armchair graphene nanoribbon field-effect transistor model
A. Avnon, R. Golman, E. Garzón, H.D Ngo, M. Lanuzza, A. Teman
Solid-State Electronics (SSE), 2021
BIB ABSTRACT
Graphene Nanoribbons (GNRs) are an emerging candidate to challenge the place of current semiconductor-based technology. In this work, we extend a model for Armchair Graphene Nanoribbons Field-Effect Transistor (AGNRFET) to the high-k dielectrics realm and examine the influences of quantum capacitance on its transient phenomena. The model is coded with Verilog-A and evaluated through SPICE simulations. We have considered a comparison between the extended model with and without the influence of the quantum capacitance. Simulation results show a realistic scenario where influence of the quantum capacitance significantly impacts the transient behaviour in circuit design. This proves the proposed model to be a valuable aid for the circuit design of future graphene-based applications.
-
-
Simulation Analysis of DMTJ-Based STT-MRAM Operating at Cryogenic Temperatures
E. Garzón, R. De Rose, F. Crupi, M. Carpentieri, A. Teman, M. Lanuzza
IEEE Transactions on Magnetics (TMAG), 2021
BIB ABSTRACT
This article investigates spin-transfer torque magnetic random access memories (STT-MRAMs) based on double-barrier magnetic tunnel junction (DMTJ) with two reference layers when operating at cryogenic temperatures. Our study is based on architecture-level estimations relying on preliminary bitcell-level electrical simulations, which have been carried out by exploiting a macrospin-based Verilog-A compact model of DMTJ, along with a 65 nm cryogenic-aware CMOS technology. Compared to conventional six-transistor static random access memory (6T-SRAM), DMTJ-based STT-MRAM proves to be faster under read access and less energy-hungry under both read/write accesses for medium to large memory sizes. Quantitatively, compared to its 6T-SRAM counterpart, a 2 MB DMTJ-based STT-MRAM operating at 77 K improves read access time by 28% and energy consumption by 52% and 38% for read and write operations, respectively. This is achieved while providing considerably lower leakage power (-98%) and a smaller on-chip area (by about 3X), at the only cost of worsened write access time.
-
-
Ultralow Voltage FinFET- Versus TFET-Based STT-MRAM Cells for IoT Applications
E. Garzón, M. Lanuzza, R. Taco, S. Strangio
Electronics, 2021
BIB ABSTRACT
Spin-transfer torque magnetic tunnel junction (STT-MTJ) based on double-barrier magnetic tunnel junction (DMTJ) has shown promising characteristics to define low-power non-volatile memories. This, along with the combination of tunnel FET (TFET) technology, could enable the design of ultralow-power/ultralow-energy STT magnetic RAMs (STT-MRAMs) for future Internet of Things (IoT) applications. This paper presents the comparison between FinFET- and TFET-based STT-MRAM bitcells operating at ultralow voltages. Our study is performed at the bitcell level by considering a DMTJ with two reference layers and exploiting either FinFET or TFET devices as cell selectors. Although ultralow-voltage operation occurs at the expense of reduced reading voltage sensing margins, simulations results show that TFET-based solutions are more resilient to process variations and can operate at ultralow voltages (<0.5 V), while showing energy savings of 50% and faster write switching of 60%.
-
-
Field-Free Magnetic Tunnel Junction for Logic Operations Based on Voltage-Controlled Magnetic Anisotropy
F. Cutugno, E. Garzón, R. De Rose, G. Finocchio, M. Lanuzza, M. Carpentieri
IEEE Magnetics Letters (IML), 2021
BIB ABSTRACT
This letter demonstrates how to perform logic operations on the data stored in magnetic tunnel junction (MTJ) devices within a memory array, without any intermediate electronic circuitry. The basic structure consists of one MTJ, exhibiting voltage-controlled magnetic anisotropy, in series connection with a MOSFET access device. The material implication and not logic operations can be performed without any external magnetic field by supplying a proper bias voltage to the circuit structure. This innovative solution enables higher energy-delay efficiency and better integration density than conventional CMOS-based computational architectures.
-
-
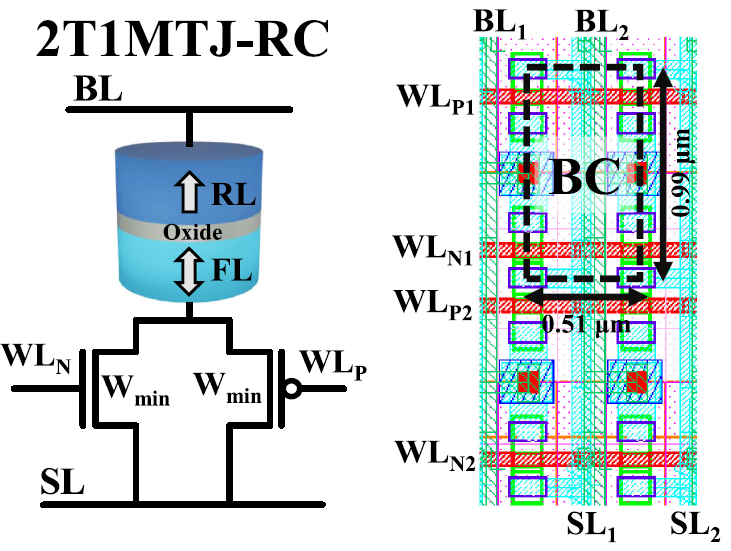
Exploiting STT-MRAMs for Cryogenic Non-Volatile Cache Applications
E. Garzón, R. De Rose, F. Crupi, A. Teman, M. Lanuzza
IEEE Transactions on Nanotechnology (TNANO), 2021
BIB ABSTRACT
This paper evaluates the potential of spin-transfer torque magnetic random-access memories (STT-MRAMs) operating at cryogenic temperatures. Our study was carried out at both circuit and architecture levels by exploiting experimental magnetic tunnel junction (MTJ) data and a CMOS technology that was fully characterized down to 77K. As a main result of our analysis, we show that for medium to large sized cache architectures, STT-MRAMs outperform their six-transistor static random access memory (6T-SRAM) counterparts at 77K in terms of both dynamic and static (leakage) power as well as read access latency, only underperforming in terms of write latency. For an 8 MB STT-MRAM cache, the read latency is improved by 2× along with a reduction of 45% and 30% in read and write energy, respectively, as compared to an SRAM implementation.
2020
-
-
Assessment of STT-MRAMs based on double-barrier MTJs for cache applications by means of a device-to-system level simulation framework
E. Garzón, R. De Rose, F. Crupi, L. Trojman, G. Finocchio, M. Carpentieri, M. Lanuzza
Integration, 2020
BIB ABSTRACT
This paper explores non-volatile cache memories implemented by spin-transfer torque magnetic random access memories (STT-MRAMs) based on state-of-the-art perpendicular magnetic tunnel junctions (MTJs) and FinFETs. The use of double-barrier MTJs with two reference layers (DMTJs) is benchmarked against solutions relying on single-barrier MTJs (SMTJs) at different technology nodes (from 28-nm down to 20-nm). Our study is carried out through a cross-layer simulation platform, starting from the device- up to the system-level. Our results point out that, thanks to the reduced switching currents, DMTJ-based STT-MRAMs allow decreasing write access time of about 63% as compared to their SMTJ-based counterparts. This is achieved while assuring reduced energy consumption under both write (−42%) and read (−28%) accesses, lower area occupancy (−40%) and smaller leakage power (−25%), at the only cost of worsened read access time. This makes DMTJ-based STT-MRAM a promising candidate to replace conventional semiconductor-based cache memory for the next-generation of low-power microprocessors with on-chip non-volatility.
-
-
Reconfigurable CMOS/STT-MTJ Non-Volatile Circuit for Logic-in-Memory Applications
E. Garzón, B. Zambrano, T. Moposita, R. Taco, L.M. Prócel, L. Trojman
IEEE 11th Latin American Symposium on Circuits & Systems (LASCAS), 2020
BIB ABSTRACT
The unique properties of spin-transfer torque magnetic tunnel junctions (STT-MTJs) have led to promising designs for logic and memory applications. Additionally, STT-MTJ based circuits have shown attractive potential to design efficient non-volatile logic-in-memory (NV-LIM) architectures, which assure low power and increased speed. This paper proposes a bit-level reconfigurable NV logic circuit based on hybrid CMOS/STT-MTJ design. Indeed, our circuit can adapt on-demand its structure, thus offering intrinsic flexibility to perform basic logic functions (i.e. AND/OR/XOR) by a single circuit architecture. Post-layout simulation results prove that the proposed circuit leads to increase both delay and energy consumption with respect to state-of-the-art non-reconfigurable designs. However, its reconfigurable operation capability is very attractive to reduce area occupation and to increase design flexibility of NV-LIM systems.
2019
-
-
Assessment of STT-MRAM performance at nanoscaled technology nodes using a device-to-memory simulation framework
E. Garzón, R. De Rose, F. Crupi, L. Trojman, M. Lanuzza
Microelectronic Engineering, 2019
BIB ABSTRACT
This paper deals with the technology scalability of spin-transfer torque magnetic RAMs (STT-MRAMs) based on nanoscaled perpendicular magnetic tunnel junctions (MTJs) and FinFET technology. Our study was performed at different levels of abstraction, from device- up to architecture-level passing through a circuit-level analysis for the single memory bitcell. Simulation results obtained for a 512 KB cache memory show that scaling from the 28-nm down to the 20-nm technology node leads to reduced write latency (−20%) and lower energy consumption under both write (−36%) and read (−29%) accesses, while also ensuring an almost doubled integration density. This occurs at the expense of slightly reduced sensing margins and higher read latency (+5%), and of a degradation in the data retention capability owing to the reduced MTJ thermal stability.
-
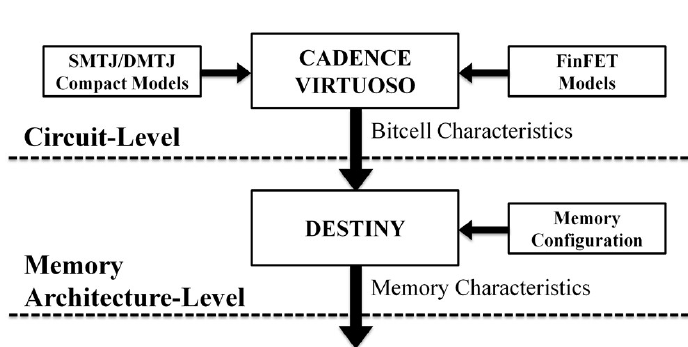
-
Exploiting Double-Barrier MTJs for Energy-Efficient Nanoscaled STT-MRAMs
E. Garzón, R. De Rose, F. Crupi, L. Trojman, G. Finocchio, M. Carpentieri, M. Lanuzza
16th International Conference on Synthesis, Modeling, Analysis and Simulation Methods and Applications to Circuit Design (SMACD), 2019
BIB ABSTRACT
This paper explores performance and technology-scalability of STT-MRAMs exploiting double-barrier MTJs (DMTJs) as comparatively evaluated with respect to conventional solution based on single-barrier MTJs (SMTJs). The comparative study was carried out at different design abstraction levels: (i) a bitcell-Ievel analysis relying on the use of Verilog-A compact models, and (ii) an architecture-level analysis for various memory sizes. Overall, our simulation results point out that, thanks to the reduced switching currents, DMTJ-based STT-MRAMs allow reducing write latency of about 60% than their SMTJ-based counterparts. This is achieved while assuring lower energy consumption under both write (-40%) and read (-27%) accesses, at the cost of reduced sensing margins.
-
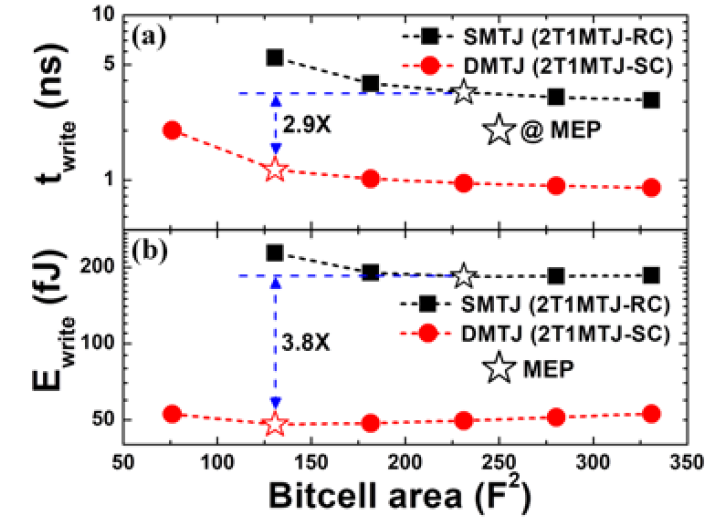
-
Evaluating the Energy Efficiency of STT-MRAMs Based on Perpendicular MTJs with Double Reference Layers
M. Lanuzza, R. De Rose, E. Garzón, F. Crupi
13th IEEE International Conference on ASIC (ASICON), 2019
BIB ABSTRACT
This paper evaluates the energy efficiency of STT-MRAMs based on double-barrier MTJs (DMTJs) as compared to conventional single-barrier MTJ (SMTJ) - based solutions. Our comparative study exploits a cross-layer simulation framework, which spreads from device-up to the architecture-level for different cache sizes. Owing to the reduced switching current, DMTJ-based STT-MRAMs prove to be credible candidates for next-generation non-volatile cache memories.
-
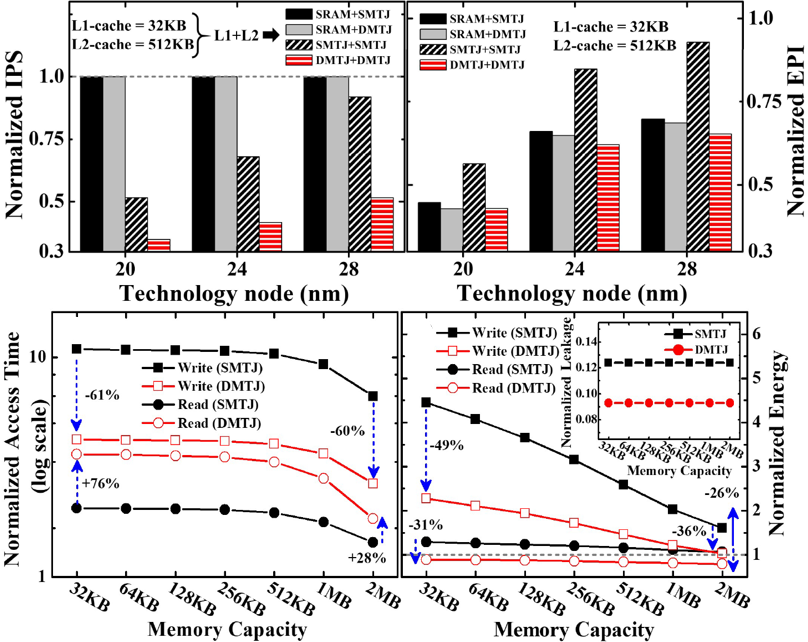
-
Device-to-System Level Simulation Framework for STT-DMTJ Based Cache Memory
E. Garzón, R. De Rose, F. Crupi, M. Lanuzza
26th IEEE International Conference on Electronics, Circuits and Systems (ICECS), 2019
BIB ABSTRACT
This paper presents a comparative study on non-volatile cache memories based on nanoscaled spin-transfer torque (STT)-magnetic tunnel junctions (MTJs). In particular, the impact of using double-barrier MTJs (DMTJs) instead of conventional single-barrier MTJs (SMTJs) is evaluated through a device-to-system level simulation framework. Simulation results demonstrate that DMTJ-based STT-MRAMs are promising competitors for the next generation of non-volatile cache memories.
-
-
Microprocessor Design with a Direct Bluetooth Connection in 45nm Technology Using Microwind
E. Garzón, F. Chávez, D. Jaramillo, L. Sánchez, S. Lara, C. Macías, E. Acurio, L.M. Prócel, L. Trojman, E. Sicard
10th IEEE Latin American Symposium on Circuits & Systems (LASCAS), 2019
BIB ABSTRACT
This paper presents the full-custom design of a 45nm microprocessor using the electronic design automation (EDA) software, Microwind. The design consists of fundamental modules: the arithmetic logic unit (ALU), memory, counter and an integrated Bluetooth (BT) port working at the 2.4 GHz. This design is validated by simulation under a process, voltage, and temperature (PVT) testing. The microprocessor can handle up to 4 bit since its purpose is focused on specific applications such as the internet of things (IoT). In order to communicate to the external world and with other devices, a strong input/output data interface and radio frequency (RF) transmission modules are implemented. Moreover, the RF module also contains a Bluetooth communication, which allows the wireless data transmission from/to the microprocessor.
2018
-
-
Capacitance Extraction of 34-nm Metallurgical Channel Length MOSFET for Parasitic Assessment Using the RFCV Technique
D. Benalcàzar, E. Garzón, L. Trojman
3rd IEEE Ecuador Technical Chapters Meeting (ETCM), 2018
BIB ABSTRACT
This paper presents the description and the results obtained with a new RFCV system written on python v2.7. which is used to acquire different parameters from MOSFET devices. RFCV is a technique that permits the measurement of capacitances from devices with an oxide thickness up into the nanometric range. Employing this technique, the developed system controls two tools in a synchronized way: a Vector Network Analyzer (VNA) and a Source Measure Unit (SMU) located in a Parameter Analyzer (PA). The obtained results are satisfactory and allow getting an adequate parameter extraction and the corresponding parasitic assessment of devices with channels as short as 34 nm.
2016
-
-
Fast computation of Cramer-Rao Bounds for TOA
E. Garzón, S. Valdiviezo, R. Játiva, J. Vidal
IEEE Latin American Conference on Computational Intelligence (LA-CCI), 2016
BIB ABSTRACT
As part of a larger scope work that studies network-based positioning, that employs timing measures, this article proposes a methodology to add Cramer-Rao Bounds (CRBs) information to the propagation model. Moreover, it enables a very quick computation of CRBs for timing, avoiding the growing computational effort resulting from Fisher's matrix formulation and its inversion for each required position at the simulation stage, assuring at the same time the reliability of the required data in the study of positioning using space-time diversity. This methodology considers the variability of the propagation conditions in terms of delay spread (DS) and Signal-to-Noise ratio (SNR) in a realistic scenario. It also coordinates the operation of concurrent models within simulation, and finally performs bi-exponential regression and interpolation procedures on pertinent operational regions for CRBs. Properly validated models provide simple closed expressions that ease the operational region discrimination and its integration to the positioning simulation platform.
-
-
Space-time diversity for NLOS mitigation in TDOA-based positioning systems
R. Játiva, E. Garzón, J. Vidal
IEEE International Engineering Summit (IE-Summit), 2016
BIB ABSTRACT
This paper studies the potential impact of using space-time information in the mitigation of the Non-Line-Of-Sight condition in mobile subscriber's positioning systems. First of all, this work discusses the positioning problem based on measures of Time Differences Of Arrival departing from a more exact characterization of the signal statistics and including some geometrical restrictions to achieve an improved accurate. Furthermore, a novel approach that integrates signal propagation characteristics to information provided by a suitable timing estimation model based on Cramer Rao Bound for a Rayleigh-fading channel, when antenna arrays are used at the receiver and when a set of channel vector estimates are available, has been introduced to study the positive benefits of space-time diversity. These approaches are evaluated within a realistic simulation scenario.
-
-
Remote control of VNA and parameter analyzer for RFCV measurements using Python
E. Garzón, F. Sanchez, L.M. Procel, L. Trojman
IEEE Technical and Scientific Conference of the Andean Council (ANDESCON), 2016
BIB ABSTRACT
This paper presents the development of capacitance measurement with RF signal (RFCV) for MOSFET. Such technic is fundamental to measure and extract capacitances from nanometric range oxide thickness, which are very leaky in low frequency range measurements. This method uses the control and synchronization of a vector network analyzer (VNA) with a Source Measure Unit (SMU) from a parameter analyzer (PA). The control is established by a remote graphical interface developed in Python. It includes the use of standards like IEEE 488.2, SCPI and Ethernet link protocol. For the RFCV measurements, the SMU provides the DC voltage whereas the VNA the RF signal.